classSolution: defminPathSum(self, grid: List[List[int]]) -> int: m, n = len(grid), len(grid[0]) @cache defdfs(x, y): if x == m - 1and y == n - 1: return grid[x][y] if x >= m or y >= n: return2000000 returnmin(dfs(x + 1, y), dfs(x, y + 1)) + grid[x][y] return dfs(0, 0)
/** * 计算从左上角到右下角有多少种不同的路径。 * @param m 目标网格的行数 * @param n 目标网格的列数 * @return 不同路径的数量 */ publicintuniquePaths(int m, int n) { // 初始化记忆化搜索的二维数组,大小为(m+1) x (n+1),预留一位用于处理边界情况 mem = newint[m + 1][n + 1];
// 将数组所有元素初始化为-1,表示尚未计算 for (inti=0 ; i <= m ; i++) { Arrays.fill(mem[i], -1 ); }
// 从起点(0, 0)开始进行深度优先搜索计算不同路径数量 return dfs(0, 0, m, n); }
/** * 深度优先搜索计算从(i, j)到(m-1, n-1)的不同路径数量。 * 利用记忆化递归减少重复计算。 * @param i 当前所在的行 * @param j 当前所在的列 * @param m 目标网格的行数 * @param n 目标网格的列数 * @return 从当前位置到终点的不同路径数量 */ privateintdfs(int i, int j, int m, int n) { // 如果到达终点,返回1表示找到一种路径 if (i == m - 1 && j == n - 1) { return1; }
// 如果越界,返回0表示此路径无效 if (i < 0 || j < 0 || i >= m || j >= n) { return0; }
// 如果当前位置的结果已经计算过,直接从记忆数组中返回结果 if (mem[i][j] != -1) { return mem[i][j]; }
// 向下和向右两个方向探索,累加两种情况下的路径数量 intans= dfs(i + 1, j, m, n) + dfs(i, j + 1, m, n);
// 将计算结果存入记忆数组,避免重复计算 mem[i][j] = ans;
// 返回计算结果 return ans; } }
1 2 3 4 5 6 7 8 9
classSolution: defuniquePaths(self, m: int, n: int) -> int: @cache defdfs(x, y): if x == m - 1and y == n - 1: return1 if x == m or y == n: return0 return dfs(x + 1, y) + dfs(x, y + 1)
// uniquePathsWithObstacles 方法用于计算在给定的有障碍物的网格中,从左上角到右下角的唯一路径数量 publicintuniquePathsWithObstacles(int[][] obstacleGrid) { // 获取网格的行数 m 和列数 n intm= obstacleGrid.length, n = obstacleGrid[0].length; // 初始化备忘录数组 mem,用于存储已经计算过的路径数量,避免重复计算 mem = newint[m][n]; // 使用 Arrays.fill 方法将备忘录数组 mem 填入 -1,表示初始时未计算过 for (inti=0; i < m; i++) { Arrays.fill(mem[i], -1); } // 调用 dfs 方法从网格的左上角 (0, 0) 开始进行深度优先搜索 return dfs(0, 0, m, n, obstacleGrid); }
// mem 备忘录数组,用于存储已经计算过的位置的路径数量 int[][] mem;
// dfs 方法是一个递归方法,用于计算从位置 (i, j) 开始到右下角 (m - 1, n - 1) 的唯一路径数量 privateintdfs(int i, int j, int m, int n, int[][] obstacleGrid) { // 如果当前位置超出网格范围或存在障碍物,则无法通过,返回 0 if (i < 0 || j < 0 || i >= m || j >= n || obstacleGrid[i][j] == 1) { return0; } // 如果到达右下角,存在 1 条路径 if (i == m - 1 && j == n - 1) { return1; } // 如果备忘录中已经计算过当前位置的路径数量,则直接返回该值 if (mem[i][j] != -1) { return mem[i][j]; } // 否则,计算当前位置向下和向右两个方向的路径数量,并将它们相加 // 将计算结果存储到备忘录中,然后返回 intans= dfs(i + 1, j, m, n, obstacleGrid) + dfs(i, j + 1, m, n, obstacleGrid); mem[i][j] = ans; return ans; } }
1 2 3 4 5 6 7 8 9 10
classSolution: defuniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int: m, n = len(obstacleGrid), len(obstacleGrid[0]) @cache defdfs(x, y): if x == m - 1and y == n - 1: return1if obstacleGrid[x][y] == 0else0 if x < 0or y < 0or x >= m or y >= n or obstacleGrid[x][y] == 1: return0 return dfs(x + 1, y) + dfs(x, y + 1) return dfs(0, 0)
classSolution { // wordBreak 方法用于检查字符串 s 是否可以由 wordDict 词汇表中的单词组成 publicbooleanwordBreak(String s, List<String> wordDict) { // 使用 HashSet 存储 wordDict 中的单词,以便快速查找 HashSet<String> set = newHashSet<>(wordDict); // 初始化备忘录数组 mem,长度与字符串 s 相同 mem = newint[s.length()]; // 调用 dfs 方法从字符串 s 的索引 0 开始进行深度优先搜索 return dfs(0, s, set); }
// mem 备忘录数组,用于存储已经计算过的索引位置的结果,0 表示未知,1 表示 true,-1 表示 false int[] mem;
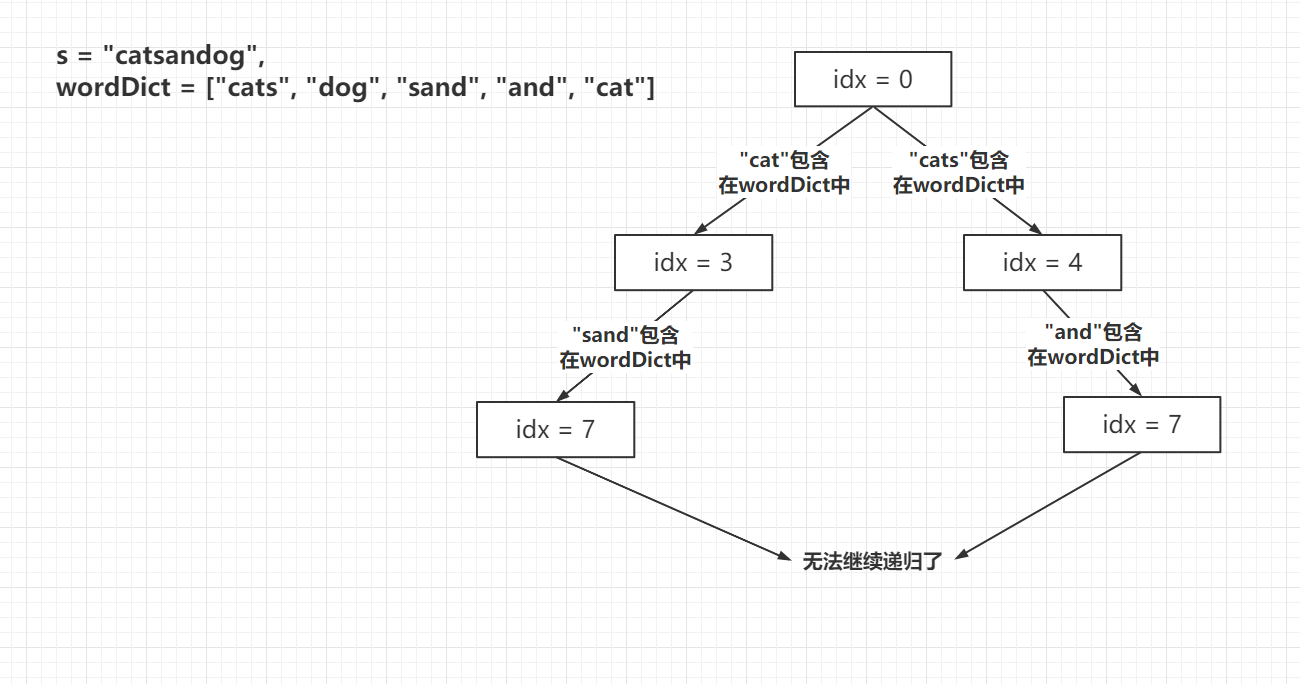
// dfs 方法是一个递归方法,用于检查从索引 idx 开始的字符串 s 是否可以由 wordDict 词汇表中的单词组成 privatebooleandfs(int idx, String s, HashSet<String> set) { // 如果当前索引 idx 大于等于字符串 s 的长度,说明已经处理到字符串末尾,返回 true if (idx >= s.length()) { returntrue; } // 如果备忘录中已经计算过当前索引 idx 的结果,则直接返回该结果 if (mem[idx] != 0) { return mem[idx] == 1; } // 初始化结果变量 ans 为 false booleanans=false; // 从当前索引 idx 开始,遍历字符串 s,直到字符串结束 for (inti= idx; i <= s.length(); i++) { // 使用 substring 方法获取从 idx 到 i 的子串 Stringtemp= s.substring(idx, i); // 如果 HashSet set 包含当前子串 temp,则递归检查从索引 i 开始的字符串 s 是否可以由 wordDict 词汇表中的单词组成 // 并将结果累加到 ans 中 if (set.contains(temp)) { ans = ans || dfs(i, s, set); } } // 将计算结果存储到备忘录数组 mem 中,如果 ans 为 true,则记为 1,否则记为 -1 mem[idx] = ans ? 1 : -1; // 返回计算结果 ans return ans; } }
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defwordBreak(self, s: str, wordDict: List[str]) -> bool: @cache defdfs(s): iflen(s) == 0: returnTrue res = False for j inrange(1,len( s) + 1): if (s[:j] in wordDict): res = dfs( s[j:]) or res return res return dfs(s)
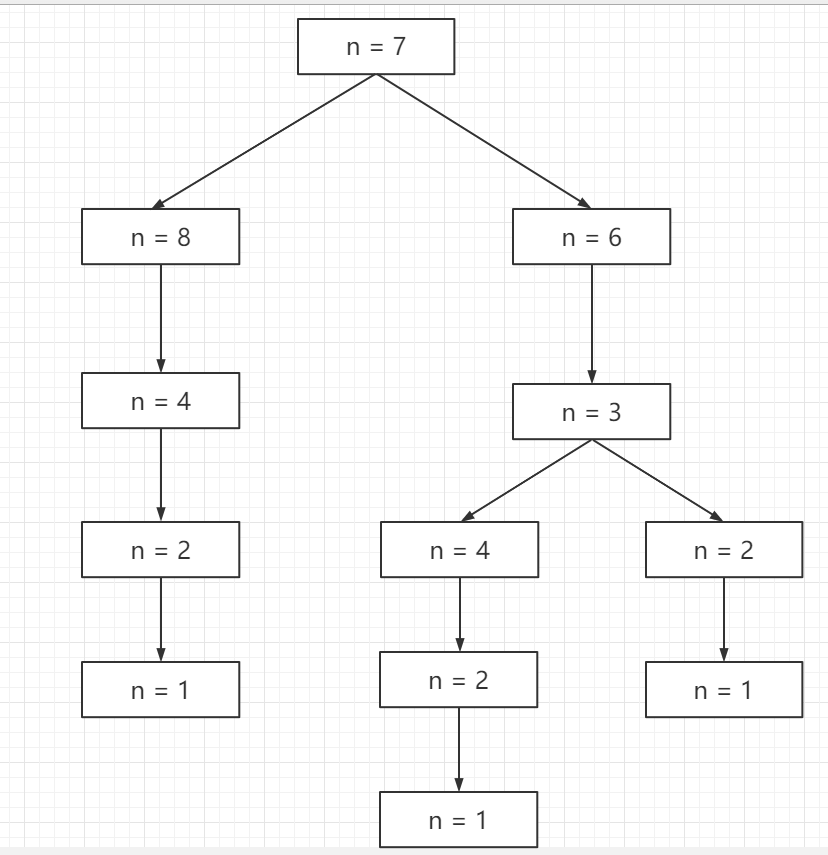
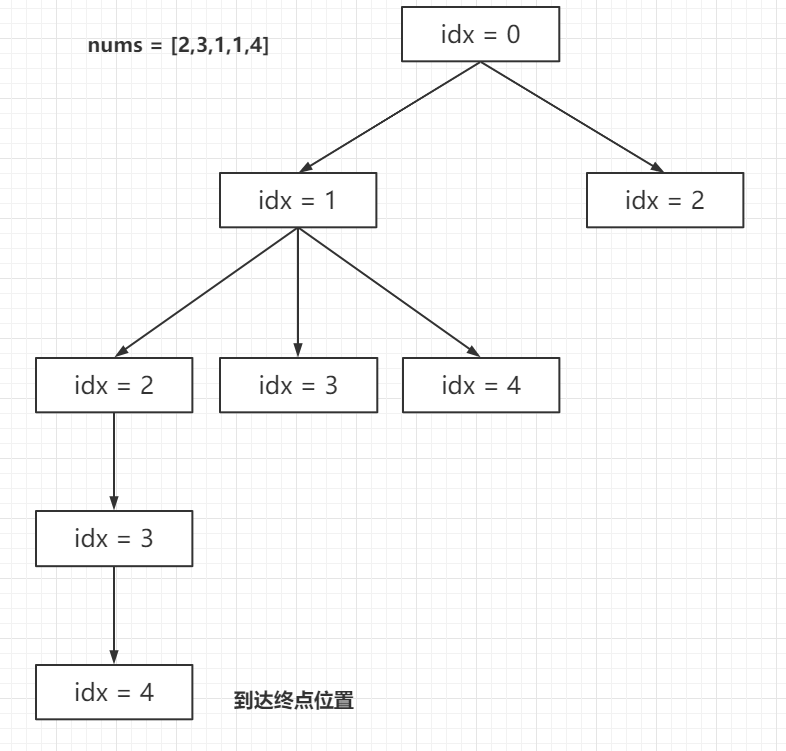
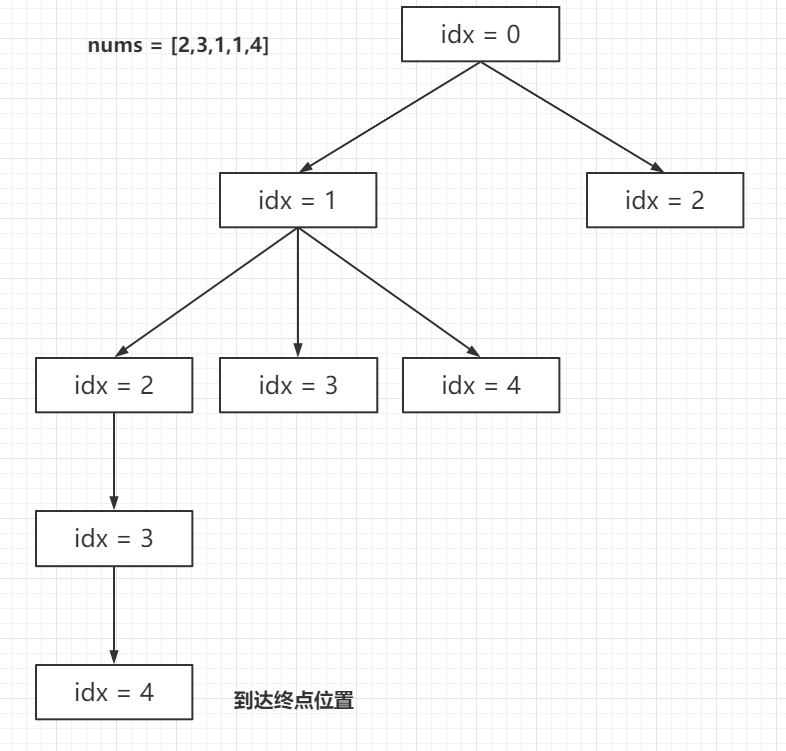
// dfs 方法是一个递归方法,用于计算从索引 idx 开始到达数组末尾的最少跳跃次数 privateintdfs(int idx, int[] nums) { // 如果当前索引 idx 已经到达或超过数组的末尾,则无需跳跃,返回 0 if (idx >= nums.length - 1) { return0; } // 如果备忘录中已经计算过当前索引 idx 的跳跃次数,则直接返回该值 if (mem[idx] != -1) { return mem[idx]; } // 初始化 ans 为一个较大的数,用于存储当前索引到达末尾的最小跳跃次数 intans=10000010; // 遍历当前索引 idx 可以跳跃到达的所有可能位置 for (inti=1; i <= nums[idx]; i++) { // 对于每个可以跳跃到达的位置,计算从该位置到达末尾的最少跳跃次数,并加上当前步的 1 次跳跃 // 使用 Math.min 更新 ans 为到达末尾的全局最小跳跃次数 ans = Math.min(ans, dfs(idx + i, nums) + 1); } // 将计算得到的最小跳跃次数存储到备忘录 mem 中 mem[idx] = ans; // 返回当前索引 idx 到达末尾的最少跳跃次数 return ans; } }
1 2 3 4 5 6 7 8 9 10 11
classSolution: defjump(self, nums: List[int]) -> int: @cache defdfs(i): if i >= len(nums) - 1: return0 ans = inf for j inrange(1, nums[i]+1): ans = min(ans, dfs(i+j) + 1) return ans