2024.4.29 计算机基础+算法
计算机基础
B站笔试
涉及的知识点总结
在 jstat 命令的使用中,有一些特定的选项用于输出 Java 虚拟机的统计信息。以下是对每个选项的解释:
jstat -gc:这个命令用于输出垃圾收集统计信息,包括堆中各区域的使用情况和垃圾收集次数等。jstat -gccause:这个命令用于输出垃圾收集统计信息以及最后一次垃圾收集的原因。jstat -gcnew:这个命令用于输出新生代的垃圾收集统计信息。jstat -gc 2 5:这个命令用于每隔 2 毫秒输出一次垃圾收集统计信息,输出5次。这里需要注意的是时间单位是ms。
Java中内存大小
理论上一个空对象占用内存大小只有对象头信息,对象头占 12 个字节。那么 ObjA.class 应该占用的存储空间就是 12 字节,考虑到 8 字节的对齐填充,那么会补上 4 字节填充到 8 的 2倍,总共就是 16字节。怎么验证我们的结论呢?JDK 提供了一个工具,JOL 全称为 Java Object Layout,是分析 JVM 中对象布局的工具,该工具大量使用了 Unsafe、JVMTI 来解码布局情况。
synchronized
锁升级的本质其实就是mark word的改变。
synchronized是非公平锁,非公平锁允许当前正在等待的线程插队,即使有其他线程在等待。因此,Synchronized可能会导致线程饥饿现象,即某些线程一直无法获取到锁。
当没有出现竞争时,默认会使用偏向锁。
分区表
分区表的优势通常包括提高性能和扩展性,优化备份和恢复,以及提高查询效率。分区表通过将数据分割成更小的逻辑部分,可以提高查询效率和备份恢复的效率,但并不一定会提高数据的安全性。数据的安全性通常与访问控制、加密和备份策略等因素有关,而不是分区表的存在与否。
多项式的帧低端补零问题
在CRC(循环冗余校验)中,为了进行除法运算,需要在待传送的数据M的低位端添加G(X)多项式的次数减一(即多项式的位数减一)个零。
树的遍历
- 前序遍历:M→L→R,递归。
- 中序遍历:L→M→R
- 后序遍历:L→R→M
在Java中,可以使用Runtime类的freeMemory()方法来获取当前JVM的空闲内存量。这个方法返回的是JVM当前可用的空闲内存量,以字节为单位。
文件管理
采取哪种文件存取方式主要取决于用户的使用要求和存储介质的特性;
在磁带上的顺序文件最后添加新的记录时不必复制整个文件;
对于一个具有二级索引表的文件,存取一个记录通常要访问一次磁盘。
索引文件的物理结构并不一定必须按照指针进行。在索引文件中,可以使用各种方法来组织索引,如B树、B+树等,这些方法可以提高文件的随机存取速度。索引文件中使用指针的存取方式可能会导致存取速度变慢,因为需要额外的指针解析操作。
jconsole
jconsole 是 Java 自带的一款监控和管理 Java 虚拟机工具。它可以对 Java 应用程序的内存、线程、类等进行可视化监控,并提供了丰富的图形化界面和功能,方便开发人员进行性能分析和调优。
分区
分区中可以使用外键约束。
一个表最多可以有1024个分区。
若分区中包含主键的列,则所有的主键列必须都包含进来。
分区不是直接基于列进行的,而是基于列上的某种值的范围或散列方式进行的。分区通常是基于表中的某个列的值的范围进行的,例如时间范围、地理位置等,而不是直接基于列进行分区。
BlockingQueue
BlockingQueue接口的实现类包括SynchronousQueue、DelayQueue和PriorityBlockingQueue,它们都是阻塞队列,而ConcurrentLinkedDeque不是。BlockingQueue的实现类特点是可以支持线程间的阻塞操作,而ConcurrentLinkedDeque则是非阻塞的。
ConcurrentLinkedDeque是Java并发包中Deque接口的一个实现类,但它并不是BlockingQueue的实现类。
链表连接
有两个单循环链表A1和A2,两个链表存在表头且分别为A1、A2,表尾分别为R1,R2,现需要将两个链表做连接操作,将A2链表连接到链表A1后,则最少的操作步数为4,其中涉及到释放操作。
- 找到A2的表头A2:需要遍历A2链表一次,以找到其表头。
- 找到A1的表尾R1:需要遍历A1链表一次,以找到其表尾。
- 将A1的表尾R1指向A2的表头A2:将A1的表尾R1的指针指向A2的表头,使得A1和A2形成一个新的循环链表。
- 释放A2的表头节点:如果需要释放A2的表头节点,那么需要将A2的表头节点从链表中移除并释放其内存。
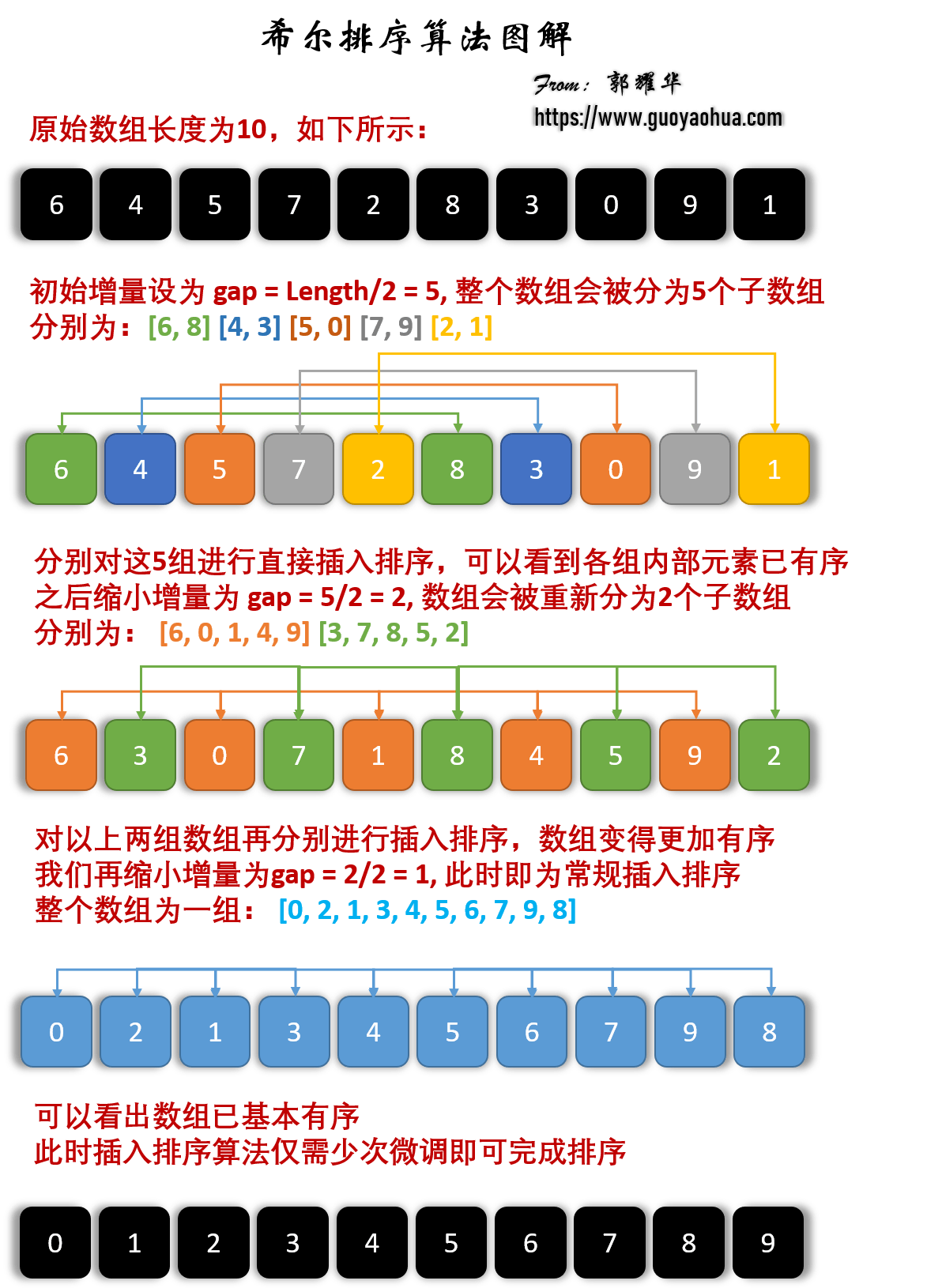
希尔排序
希尔排序是希尔 (Donald Shell) 于 1959 年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为递减增量排序算法,同时该算法是冲破 𝑂(𝑛2) 的第一批算法之一。
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录 “基本有序” 时,再对全体记录进行依次直接插入排序。
基本步骤
我们来看下希尔排序的基本步骤,在此我们选择增量 𝑔𝑎𝑝=𝑙𝑒𝑛𝑔𝑡ℎ/2,缩小增量继续以 𝑔𝑎𝑝=𝑔𝑎𝑝/2 的方式,这种增量选择我们可以用一个序列来表示,,称为增量序列。希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。此处我们做示例使用希尔增量。
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
- 选择一个增量序列 ,其中 ;
- 按增量序列个数 k,对序列进行 k 趟排序;
- 每趟排序,根据对应的增量 t,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
算法
B站算法
1 找牛牛
青牛小学一年一度的六一儿童节开始了。现在牛牛们围成一圈坐在草地上,为了方便,我们把牛牛们编号为牛1,牛2,牛3,牛n。
其中牛1与牛2相邻,牛2与牛3相邻,牛n和牛1相邻。
为了更好的安排接下来的活动,牛老师很好奇:从这些牛中选出几只相邻的牛,总共有多少种不同的方案?
我们认为两个方案不同,当且仅当两种选法选出的牛个数不同或选出的牛的编号不完全相同
输入描述
输入一个整数n,表示牛的个数
输出描述
输出一个整数n,表示方案数
补充说明
1 | |
1 | |
思路与代码
思路非常简单,模拟推理
基本思路:观察问题,我们需要计算从n头牛中选出若干头相邻的牛的方案数。由于牛是围成一圈的,这意味着我们可以从任意一头牛开始数。
分解问题:
- 不特殊的方案:首先考虑所有的牛都不同时被选中的情况。在这种情况下,我们可以选择任意一头牛作为起点(有n种选择),然后选择从这头牛开始的任意连续数量的牛(1到n-1种选择,因为如果选择了n头,那就是特殊情况了)。因此,这部分的方案数为 (n *(n-1)。
- 特殊方案:所有的牛都被选中的情况。这是一个特殊的方案,因为不管从哪头牛开始数,选出的都是全部的牛。这种情况下只有1种方案。
总结方案数:将上述两种情况相加,得到的总方案数就是 n*(n-1)+1。
1 | |
2 翻转字符串
给出一个长度为n的字符串s和一个整数k,现在请你依次按照i= 1,2,…n-k+1的顺序求出以下操作得到的字符串将字符串s的第i个字符至第i+k- 1之间的所有字符翻转。 求出最终状态的字符串。 例如:n是5,是3,s是"hello"。 i=1时,翻转[1,3]之间的字符,得到"lehlo" i=2时,翻转 [2,4]之间的字符,得到"llheo" i=3时,翻转 [3,5]之间的字符,得到"lloeh" 因此,最终的s为"lloeh"。
输入描述
第一行输入正整数n,k。
第二行输入仅由小写字母构成的字符串s。 2≤k≤n≤2x10^5
输出描述
输出s经过翻转后的最终状态。
1 | |
思路与代码
跟上一题类似,需要想象一下这个过程,从第k个字符被翻转,更多是逻辑吧,思路如下:
- 操作次数:首先,注意到对于每个
i从 1 到n-k+1,我们会进行n-k+1次翻转操作。 - 奇偶性分析:对于任何给定的一段长度,连续两次完全相同的翻转将会抵消,即字符序列会恢复到翻转前的状态。因此,如果一个字符被翻转奇数次,它的最终位置会与初始位置不同;如果被翻转偶数次,它的最终位置会与初始位置相同。
- 翻转的影响范围:在这个问题中,每次翻转的影响范围是固定长度的(k个字符),并且随着
i的递增,这个翻转窗口在字符串上滑动。 - 特定位置的翻转次数
- 对于字符串
s的前k-1个字符和后k-1个字符,随着翻转窗口的滑动,它们的翻转次数会从 1 逐渐增加到k,然后再逐渐减少到 1。这意味着,如果n-k是奇数,则这部分字符的翻转次数为奇数;如果n-k是偶数,则翻转次数为偶数。 - 对于字符串的其余部分,即从第
k个字符到第n-k个字符,每个字符会被翻转k次,这是一个固定的偶数次。
- 对于字符串
正确代码:
1 | |
不能按模拟,比如以下方法,字符串很多的情况会浪费很多时间:
1 | |
由于 n-k+1 是翻转窗口滑动的次数,它等于字符串长度 n 减去翻转窗口的长度 k 再加 1。因为 n 和 k 都是正整数,所以 n-k+1 一定是一个正整数。
重要的是,无论 n-k+1 是奇数还是偶数,对于中间的字符来说,它们被翻转的次数实际上是 2 * (n-k+1),因为每次翻转操作实际上是两次位置交换(即一个字符被翻转两次)。因此,无论 n-k+1 是奇数还是偶数,中间字符被翻转的次数总是偶数。