摘要:无人机( uav )被设想为未来智能城市中 5G 通信基础设施的补充。在交叉口容易出现热点,车辆之间的有效沟通是一个挑战。uav 可以作为继电器,具有价格低、易于部署、视线范围连接和灵活的机动性等优点。在本文中,我们研究了无人机辅助的车载网络,无人机联合调整其传输控制(功率和信道)和三维飞行,以最大限度地提高总吞吐量。首先,通过对无人机/车辆的机动性和状态转换建模,构建了马尔可夫决策过程( MDP )问题。其次,在未知或不可测的环境变量下,特别是在5G环境下,利用深度强化学习方法解决目标问题,即深度确定性策略梯度( DDPG ),并提出了三种不同控制目标的解决方案。环境变量是未知和不可测量的,因此,我们使用深度强化学习方法。此外,考虑到 3D 飞行的能源消耗,我们扩展了所提出的解决方案,通过鼓励或阻止无人机的机动性,使每能量单位的总吞吐量最大化。为了实现这个目标, DDPG 框架被修改了。然后,在一个具有较小状态空间和动作空间的简化模型中,验证了所提算法的最优性。通过与两种基线方案的比较,验证了所提算法在真实模型中的有效性。
关键词:无人机、车载网络、智慧城市、马尔可夫决策过程、深度强化学习、功率控制、信道控制
智能交通系统是智能城市的关键组成部分,它利用实时数据通信实现交通监控、路径规划、娱乐和广告等功能。高速车辆网络是智能交通系统的关键组成部分,它提供合作通信以提高数据传输性能。随着车辆数量的增加,现有的通信基础设施可能无法满足数据传输的需求,特别是在交通高峰期出现热点(如道路交叉口)时。无人机( UAVs )或无人机( drones )可以补充 4G/5G 通信基础设施,包括车对车( V2V )通信和车对基础设施( V2I )通信。高通公司已获得授权认证,允许在 400 英尺以下进行无人机测试;华为将与中国移动合作建立首个区域物流无人机的蜂窝测试网络。
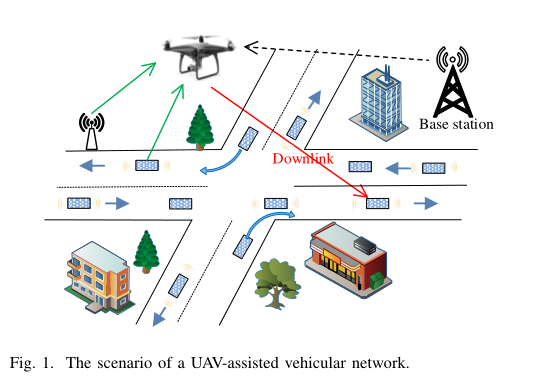
图 1 中的无人机辅助车载网络有几个优点。首先,由于与固定的基站相比,无人机可以更接近车辆,因此路径损失将大大降低。其次,该无人机能够根据车辆的机动性灵活地调整传输控制。第三,无人机-车辆链路的质量普遍优于地面链路,因为它们大多是视距无线传输( LoS )。
最大化无人机-车辆链路的总吞吐量有几个挑战。首先,通信通道随着无人机三维位置的变化而变化。其次,传统优化方法无法直接求解无人机三维飞行与传动控制(如功率控制)的联合调整问题,特别是在环境变量未知且不可测的情况下。第三,通道条件难以获取,如无人机到车辆的路径损失与建筑物高度/密度和街道宽度密切相关。
本文提出了深度强化学习算法,以最大化无人机对飞行器通信的总吞吐量,通过与环境的交互学习,共同调整无人机的三维飞行和传输控制。本文的主要贡献如下:
1)将该问题定义为马尔可夫决策过程( MDP )问题,以总传输功率和总信道为约束,使总吞吐量最大化;
2)应用深度强化学习方法——深度确定性策略梯度( DDPG )来解决该问题。 DDPG 适用于具有连续状态和连续行动的 MDP 问题。提出了三种不同控制目标的方案,共同调整无人机的三维飞行和传输控制。然后,我们扩展提出的解决方案,以最大限度地总吞吐量每能源单位。为了鼓励或抑制无人机的机动性,我们修改了奖励函数和 DDPG 框架;
3)利用一个简化模型,在较小的状态空间和动作空间下,验证了所提解的最优性。
最后,我们提供了大量的仿真结果,以证明所提出的解决方案的有效性,并与两个基线方案进行了比较。
本文的其余部分组织如下。第二节讨论相关工作。第三节介绍系统模型和问题表述。第四节提出了解决方案。第五节给出了绩效评估。第六部分是本文的总结。
无人机辅助车载网络的动态控制包括飞行控制和传输控制。飞行控制主要包括飞行路径、时间和方向的规划。Yang 等人提出了一种联合遗传算法和蚁群优化方法来获得无人机在无线传感器网络中收集感知数据的最佳飞行路径。为了进一步最小化无人机在一定约束条件(如能量限制、公平性、碰撞等)下的飞行时间,Garraffa 等人提出了一种基于列生成方法的二维( 2D )路径规划方法。Liu 等人提出了一种深度强化学习方法,通过优化飞行方向和距离来控制一组无人机,在有限的能量消耗下实现长期最佳的通信覆盖。
无人机的传输控制主要涉及接入选择、传输功率、带宽/信道分配等资源分配问题。Wang 等人提出了一种考虑通信、缓存和能量传输的无人机功率分配策略。在无人机辅助通信网络中,Yan 等人研究了无人机接入选择和基站带宽分配问题,将无人机与基站之间的交互建模为 Stackelberg 博弈,得到了 纳什均衡的唯一性。
同时考虑了无人机飞行和传输的联合控制。 Wu 等人通过联合优化无人机的二维轨迹和功率分配,考虑最大限度地提高无人机到地面用户的最小可达率。 Zeng 等人提出了一种凸优化方法,对无人机的二维轨迹进行优化,使其任务完成时间最小化,同时保证无人机向各地面终端传播一个公共文件时,各地面终端高概率恢复文件。Zhang 等人考虑了无人机任务完成时间的最小化问题,以基站与无人机之间的连接质量为约束,对无人机的二维轨迹进行优化。然而,现有的研究大多忽略了通过规避各种障碍物或非视距( NLoS )链路来调整无人机的高度以获得更好的链路质量。
Fan 等对无人机的三维飞行和传输控制进行了优化;但根据 LoS link 的要求,将 3D 位置优化转换为 2D 位置优化。现有的基于深度强化学习的方法只处理无人机的 2D 飞行和简单的传输控制决策。例如,Challita 等人提出了一种基于深度强化学习的蜂窝无人机网络方法,通过优化二维路径和小区关联,实现了能量效率最大化和无线延迟和路径干扰最小化之间的权衡。在文章23中应用了一个类似的方案来提供智能交通灯控制。
此外,现有的大多数工程都假定接地端子是固定的;而在现实中,一些地面终端以特定的模式移动,例如,车辆在交通灯的控制下移动。本文研究了一种考虑交叉口车辆移动性的无人机辅助车载网络,该网络可以联合调整无人机的三维飞行和传输控制。
在本节中,我们首先描述了交通模型和通信模型,然后将目标问题表述为一个马尔可夫决策过程。为了便于参考,通讯模型中的变量列于表 1 。
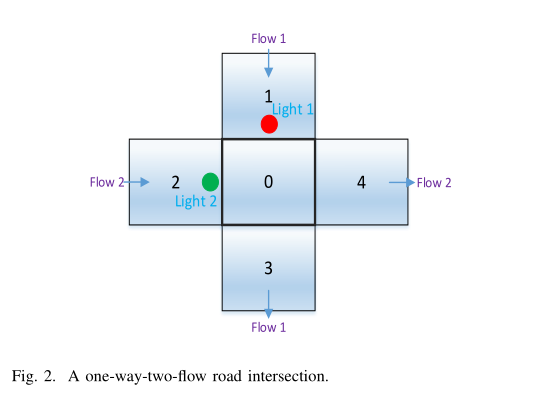
我们从图 2 所示的单向双流路口开始,而图 7 中更为复杂的场景将在V-B部分中描述。五个街区被编号为0、1、2、3、4,其中 0 街区是交叉口。假设每个 block 最多包含一个 vehicle ,用二进制变量 n 表示,n = (n0,…∈{0,1}。图 2 中有两条交通流,
“Flow 1”:1→0→3; “Flow 2”:2→0→4. 交通灯 L 有四种配置:
L = 0: flow 1为红灯, flow 2为绿灯; L = 1: flow 1为红灯, flow 2为黄灯; L = 2: flow 1为绿灯, flow 2为红灯; L = 3: flow 1为黄灯, flow 2为红灯。
时间被划分为持续时间相等的插槽。绿灯、红灯的持续时间占用N个时隙,黄灯的持续时间占用一个时隙,如图3所示。假设绿灯亮时,每辆车在一个时间段内移动一个街区
我们的重点是下行通信( UAV- vehicle ),因为它们直接由 UAV 控制。每个无人机 -车辆链路有两种通道状态,视距( LoS )和非视距( NLoS)。设 x 、 z 分别表示无人机的块(水平位置)和高度,其中 x∈{0,1,2,3,4} 对应图 2 中的这五个块,将z离散为多个值。我们假设无人机停留在五个街区以上,因为无人机倾向于靠近车辆。接下来,我们描述了通信模型,包括信道功率增益、信噪比和总吞吐量。
首先,以信道状态 H t i ∈ N L o S , L o S H_t^i \in {NLoS, LoS} H t i ∈ N L o S , L o S h i h^i h i
h t i = { ( D t i ) − β 1 , if H t i = L o S β 2 ( D t i ) − β 1 , if H t i = N L o S h_{t}^{i}=\left\{\begin{array}{ll} \left(D_{t}^{i}\right)^{-\beta_{1}}, & \text { if } H_{t}^{i}=\mathrm{LoS} \\ \beta_{2}\left(D_{t}^{i}\right)^{-\beta_{1}}, & \text { if } H_{t}^{i}=\mathrm{NLoS} \end{array}\right. h t i = { ( D t i ) − β 1 , β 2 ( D t i ) − β 1 , if H t i = L o S if H t i = N L o S
式中 D t i D_{t}^{i} D t i β 1 \beta_{1} β 1 β 2 \beta_{2} β 2
t 时隙中无人机与 i 块车辆之间的视距链路和非视距链路的概率为
p ( H t i = L o S ) = 1 1 + α 1 exp ( − α 2 ( 180 π arctan z d t i − α 1 ) ) p ( H t i = N L o S ) = 1 − p ( H t i = L o S ) , i ∈ { 0 , 1 , 2 , 3 , 4 } \begin{array}{c} p\left(H_{t}^{i}=\mathrm{LoS}\right)=\frac{1}{1+\alpha_{1} \exp \left(-\alpha_{2}\left(\frac{180}{\pi} \arctan \frac{z}{d_{t}^{i}}-\alpha_{1}\right)\right)} \\ p\left(H_{t}^{i}=\mathrm{NLoS}\right)=1-p\left(H_{t}^{i}=\mathrm{LoS}\right), \quad i \in\{0,1,2,3,4\} \end{array} p ( H t i = L o S ) = 1 + α 1 e x p ( − α 2 ( π 1 8 0 a r c t a n d t i z − α 1 ) ) 1 p ( H t i = N L o S ) = 1 − p ( H t i = L o S ) , i ∈ { 0 , 1 , 2 , 3 , 4 }
其中,α 1 \alpha_1 α 1 α 2 \alpha_2 α 2 α 1 \alpha_1 α 1 α 2 \alpha_2 α 2 β 1 \beta_1 β 1 β 2 \beta_2 β 2 180 π arctan z d t i \frac{180}{\pi} \arctan \frac{z}{d_{t}^{i}} π 1 8 0 arctan d t i z d t i d_{t}^{i} d t i z t z_t z t D t i = ( d t i ) 2 + z t 2 D_{t}^{i}=\sqrt{\left(d_{t}^{i}\right)^{2}+z_{t}^{2}} D t i = ( d t i ) 2 + z t 2
其次,将无人机到块 i 车辆在 t 时段的 SINR ψ t i \psi_{t}^{i} ψ t i
ψ t i = ρ t i h t i b c t i σ 2 , i ∈ { 0 , 1 , 2 , 3 , 4 } \psi_{t}^{i}=\frac{\rho_{t}^{i} h_{t}^{i}}{b c_{t}^{i} \sigma^{2}}, i \in\{0,1,2,3,4\} ψ t i = b c t i σ 2 ρ t i h t i , i ∈ { 0 , 1 , 2 , 3 , 4 }
式中, b 为每个信道的等带宽, ρ t i \rho_{t}^{i} ρ t i c t i c_{t}^{i} c t i σ 2 \sigma^{2} σ 2 h i h^i h i
第三,无人机到车辆链路的总吞吐量(reward)表示为:
∑ i ∈ { 0 , 1 , 2 , 3 , 4 } b c t i log ( 1 + ψ t i ) = ∑ i ∈ { 0 , 1 , 2 , 3 , 4 } b c t i log ( 1 + ρ t i h t i b c t i σ 2 ) \sum_{i \in\{0,1,2,3,4\}} b c_{t}^{i} \log \left(1+\psi_{t}^{i}\right)=\sum_{i \in\{0,1,2,3,4\}} b c_{t}^{i} \log \left(1+\frac{\rho_{t}^{i} h_{t}^{i}}{b c_{t}^{i} \sigma^{2}}\right) i ∈ { 0 , 1 , 2 , 3 , 4 } ∑ b c t i log ( 1 + ψ t i ) = i ∈ { 0 , 1 , 2 , 3 , 4 } ∑ b c t i log ( 1 + b c t i σ 2 ρ t i h t i )
无人机的目标是在总传输功率和总信道约束下实现总吞吐量最大化:
\sum_{i \in\{0,1,2,3,4\}} \rho_{t}^{i} \leq P, \quad \sum_{i \in\{0,1,2,3,4\}} c_{t}^{i} \leq C, \\ {0 \leq \rho_{t}^{i} \leq \rho_{\max },} &{0 \leq c_{t}^{i} \leq c_{\max }, \quad i \in\{0,1,2,3,4\},}
其中 P 为总传输功率, C 为总信道数, ρ max \rho_{\max } ρ m a x c max c_{\max } c m a x ρ t i \rho_{t}^{i} ρ t i c t i c_{t}^{i} c t i
将无人机辅助通信建模为马尔可夫决策过程( MDP )。一方面,由公式( 2 )和公式( 3 )可知,无人机-飞行器链路的信道状态服从随机过程。另一方面,车辆到达在红绿灯控制下遵循随机过程,如(12)(13)。
在 MDP 框架下,问题的状态空间 S 、行动空间 A 、奖励 r 、策略 π 和状态转移概率 p ( s t + 1 ∣ s t , a t ) p\left(s_{t+1} \mid s_{t}, a_{t}\right) p ( s t + 1 ∣ s t , a t )
1.状态State S = ( L , x , z , n , H ) \mathcal{S}=(L, x, z, \boldsymbol{n}, \boldsymbol{H}) S = ( L , x , z , n , H ) H = ( H 0 , … , H 4 ) \boldsymbol{H}=\left(H^{0}, \ldots, H^{4}\right) H = ( H 0 , … , H 4 ) H i H^i H i z ∈ [ z min , z max ] z \in\left[z_{\min }, z_{\max }\right] z ∈ [ z m i n , z m a x ] z min z_{\min } z m i n z max z_{\max } z m a x
2.动作Action A = ( f , ρ , c ) A = (f,ρ,c) A = ( f , ρ , c ) f x f^x f x f z f^z f z f = ( f x , f z ) \boldsymbol{f}=\left(f^{x}, f^{z}\right) f = ( f x , f z ) f x ∈ { 0 , 1 , … , 7 } f^{x} \in\{0,1, \ldots, 7\} f x ∈ { 0 , 1 , … , 7 }
f z ∈ { − 5 , 0 , 5 } , f^{z} \in\{-5,0,5\}, f z ∈ { − 5 , 0 , 5 } ,
这意味着无人机可以在一个时间段内向下飞行5米,水平飞行5米,向上飞行5米。无人机的高度可以表示为
z t + 1 = f t z + z t z_{t+1}=f_{t}^{z}+z_{t} z t + 1 = f t z + z t
$\boldsymbol{\rho}=\left(\rho_{t}^{0}, \ldots, \rho_{t}^{4}\right) $ 和 $ \boldsymbol{c}=\left(c_{t}^{0}, \ldots, c_{t}^{4}\right)$ 分别为这五个块的传输功率和信道分配动作。在时间t结束时,无人机根据动作 f 移动到一个新的 3D 位置,随着时间 t 的推移,发射功率为 ρ ,信道数为 c 。
3.奖励Reward r ( s t , a t ) = ∑ i ∈ { 0 , 1 , 2 , 3 , 4 } b n t i c t i log ( 1 + ρ t i h t i b c t i σ 2 ) r\left(s_{t}, a_{t}\right)=\sum_{i \in\{0,1,2,3,4\}} b n_{t}^{i} c_{t}^{i} \log \left(1+\frac{\rho_{t}^{i} h_{t}^{i}}{b c_{t}^{i} \sigma^{2}}\right) r ( s t , a t ) = ∑ i ∈ { 0 , 1 , 2 , 3 , 4 } b n t i c t i log ( 1 + b c t i σ 2 ρ t i h t i ) a t a_t a t s t s_t s t s t + 1 s_{t+1} s t + 1 s t = ( L t , x t , z t , n t , H t ) s_t = \left(L_{t}, x_{t}, z_{t}, \boldsymbol{n}_{t}, \boldsymbol{H}_{t}\right) s t = ( L t , x t , z t , n t , H t )
4.策略Policy π 是无人机的策略,它将状态映射到行动 π 上的概率分布 π : S → P ( A ) \pi: \mathcal{S} \rightarrow \mathcal{P}(\mathcal{A}) π : S → P ( A ) P ( ⋅ ) \mathcal{P}(\cdot) P ( ⋅ ) s t = ( L t , x t , z t , n t , H t ) s_{t}=\left(L_{t}, x_{t}, z_{t}, \boldsymbol{n}_{t}, \boldsymbol{H}_{t}\right) s t = ( L t , x t , z t , n t , H t ) π t \pi_t π t
5.状态转换概率 p ( s t + 1 ∣ s t , a t ) p\left(s_{t+1} \mid s_{t}, a_{t}\right) p ( s t + 1 ∣ s t , a t ) s t s_t s t a t a_t a t s t + 1 s_{t+1} s t + 1 s t = ( L t , x t , z t , n t , H t ) s_{t}=\left(L_{t}, x_{t}, z_{t}, \boldsymbol{n}_{t}, \boldsymbol{H}_{t}\right) s t = ( L t , x t , z t , n t , H t ) a t = ( f , ρ , c ) a_{t}=(\boldsymbol{f}, \boldsymbol{\rho}, \boldsymbol{c}) a t = ( f , ρ , c ) ( x t + 1 , z t + 1 ) (x_{t+1}, z_{t+1}) ( x t + 1 , z t + 1 ) H t + 1 H_{t+1} H t + 1 L t + 1 L_{t+1} L t + 1 n t + 1 n_{t+1} n t + 1
交通灯的状态随时间的变化如图 3 所示。无人机 -车辆链路信道状态的转变是一个随机过程,由式(2)和式(3)反映。
其次,从状态转移概率、每个块内车辆数状态转移和无人机的三维位置三个方面讨论状态转移算法。需要注意的是,传输功率控制和通道控制不影响交通灯、通道状态、车辆数量和无人机三维位置。
首先,我们讨论了状态转移概率 p ( s t + 1 ∣ s t , a t ) = p ( ( L t + 1 , x t + 1 , z t + 1 , n t + 1 , H t + 1 ) ∣ ( L t , x t , z t , n t , H t ) , ( f t , ρ t , c t ) ) p\left(s_{t+1} \mid s_{t}, a_{t}\right)=\quad p\left(\left(L_{t+1}, x_{t+1}, z_{t+1}, \boldsymbol{n}_{t+1}, \boldsymbol{H}_{t+1}\right)\right. \left.\mid\left(L_{t}, x_{t}, z_{t}, \boldsymbol{n}_{t}, \boldsymbol{H}_{t}\right), \quad\left(\boldsymbol{f}_{t}, \boldsymbol{\rho}_{t}, \boldsymbol{c}_{t}\right)\right) p ( s t + 1 ∣ s t , a t ) = p ( ( L t + 1 , x t + 1 , z t + 1 , n t + 1 , H t + 1 ) ∣ ( L t , x t , z t , n t , H t ) , ( f t , ρ t , c t ) )
p ( s t + 1 ∣ s t , a t ) = p ( x t + 1 , z t + 1 ∣ x t , z t , f t ) × p ( H t + 1 ∣ x t , z t , f t ) × p ( L t + 1 ∣ L t ) × p ( n t + 1 ∣ L t , n t ) \begin{aligned} p\left(s_{t+1} \mid s_{t}, a_{t}\right)=& p\left(x_{t+1}, z_{t+1} \mid x_{t}, z_{t}, \boldsymbol{f}_{t}\right) \\ & \times p\left(\boldsymbol{H}_{t+1} \mid x_{t}, z_{t}, \boldsymbol{f}_{t}\right) \times p\left(L_{t+1} \mid L_{t}\right) \\ & \times p\left(\boldsymbol{n}_{t+1} \mid L_{t}, \boldsymbol{n}_{t}\right) \end{aligned} p ( s t + 1 ∣ s t , a t ) = p ( x t + 1 , z t + 1 ∣ x t , z t , f t ) × p ( H t + 1 ∣ x t , z t , f t ) × p ( L t + 1 ∣ L t ) × p ( n t + 1 ∣ L t , n t )
其中, p ( x t + 1 , z t + 1 ∣ x t , z t , f t ) p\left(x_{t+1}, z_{t+1} \mid x_{t}, z_{t}, \boldsymbol{f}_{t}\right) p ( x t + 1 , z t + 1 ∣ x t , z t , f t ) p ( H t + 1 ∣ x t , z t , f t ) p\left(\boldsymbol{H}_{t+1} \mid x_{t}, z_{t}, \boldsymbol{f}_{t}\right) p ( H t + 1 ∣ x t , z t , f t ) p ( L t + 1 ∣ L t ) p\left(L_{t+1} \mid L_{t}\right) p ( L t + 1 ∣ L t ) p ( n t + 1 ∣ L t , n t ) p\left(\boldsymbol{n}_{t+1} \mid L_{t}, \boldsymbol{n}_{t}\right) p ( n t + 1 ∣ L t , n t )
其次,讨论了每个区块内车辆数量的状态转换。这是一个随机过程。无人机的状态和动作不影响所有区块的车辆数量。设 λ1 和 λ2 分别为Flow 1 和 2 的新车到达的概率。
block 0、block 3、block 4中车辆数量的状态转换为
n t + 1 0 = { n t 2 , if L t = 0 n t 1 , if L t = 2 0 , otherwise n t + 1 3 = { n t 0 , if L t = 2 , 3 0 , otherwise n t + 1 4 = { n t 0 , if L t = 0 , 1 , 0 , otherwise \begin{array}{l} n_{t+1}^{0}=\left\{\begin{array}{ll} n_{t}^{2}, & \text { if } L_{t}=0 \\ n_{t}^{1}, & \text { if } L_{t}=2 \\ 0, & \text { otherwise } \end{array}\right. \\ n_{t+1}^{3}=\left\{\begin{array}{ll} n_{t}^{0}, & \text { if } L_{t}=2,3 \\ 0, & \text { otherwise } \end{array}\right. \\ n_{t+1}^{4}=\left\{\begin{array}{ll} n_{t}^{0}, & \text { if } L_{t}=0,1, \\ 0, & \text { otherwise } \end{array}\right. \end{array} n t + 1 0 = ⎩ ⎪ ⎨ ⎪ ⎧ n t 2 , n t 1 , 0 , if L t = 0 if L t = 2 otherwise n t + 1 3 = { n t 0 , 0 , if L t = 2 , 3 otherwise n t + 1 4 = { n t 0 , 0 , if L t = 0 , 1 , otherwise
公式( 9 )、( 10 )、( 11 )中的转移概率为 1 ,因为在 0 、 3 、 4 块中的转移是确定性的。而block 1 和block 2 中车辆数量的状态转移概率是不确定的,并且两者都受到当前车辆数量和红绿灯的影响。以交通灯状态 L t = 2 L_t = 2 L t = 2
p ( n t + 1 1 = 1 ∣ L t = 2 ) = λ 1 p ( n t + 1 1 = 0 ∣ L t = 2 ) = 1 − λ 1 \begin{array}{l} p\left(n_{t+1}^{1}=1 \mid L_{t}=2\right)=\lambda_{1} \\ p\left(n_{t+1}^{1}=0 \mid L_{t}=2\right)=1-\lambda_{1} \end{array} p ( n t + 1 1 = 1 ∣ L t = 2 ) = λ 1 p ( n t + 1 1 = 0 ∣ L t = 2 ) = 1 − λ 1
当 ( n t 1 = 0 , L t ≠ 2 ) \left(n_{t}^{1}=0, L_{t} \neq 2\right) ( n t 1 = 0 , L t = 2 ) ( n t 1 = 1 , L t ≠ 2 ) \left(n_{t}^{1}=1, L_{t} \neq 2\right) ( n t 1 = 1 , L t = 2 )
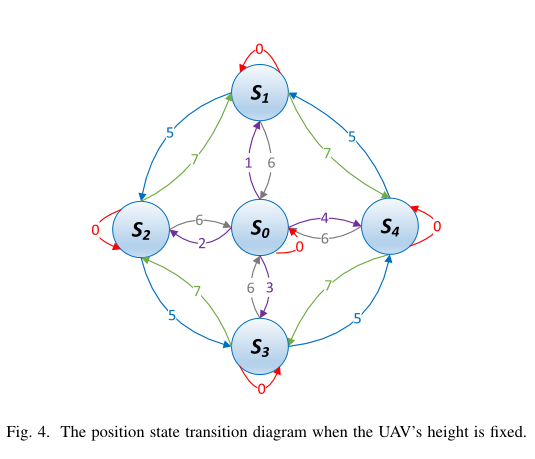
第三,讨论了无人机三维位置的状态转换。它包括块转换和高度转换。无人机的高度转移如公式( 7 )表示,当无人机高度固定时,对应的位置状态转移图如图4所示,其中 { S i } i ∈ { 0 , 1 , 2 , 3 , 4 } \{S_i\}_{i\in \{0,1,2,3,4\}} { S i } i ∈ { 0 , 1 , 2 , 3 , 4 }
在本节中,我们首先描述了动机,然后介绍了 Q-learning 和深度确定性策略梯度算法的概述,然后提出了不同控制目标的解决方案,最后给出了考虑 3D 飞行能量消耗的扩展解决方案。
由于环境变量是未知且不可测量的,因此深度强化学习方法适用于该目标问题。例如, α1 和 α2 受建筑物的高度/密度、车辆的高度和大小等的影响。 β1 和 β2 具有时间依赖性,并受当前环境如天气的影响。虽然无人机可以使用装备的摄像机探测 LoS/NloS 链路,但由于几个原因,准确探测它们是非常具有挑战性的。首先,车辆上的接收器的位置应该被标记,以便检测。其次,由于接收机比车辆小得多,使用计算机视觉技术很难准确地检测接收机。第三,它要求汽车制造商标明接收器的位置,这可能在几年之内都不能满足。因此,准确地测试这些环境变量需要大量的劳动。即使环境变量已知,也很难获得最优策略。现有的作品在用户静止的情况下获得了 2D 飞行场景下的近最优策略,但由于无人机会调整其三维位置,车辆在交通灯的控制下会按自己的模式移动,因此无法解决我们的目标问题。
在我们的问题中 MDP 的状态转移概率是未知的,因为一些变量是未知的,如 α1 , α2 , λ1 和 λ2 。我们的问题不能直接用传统的 MDP 算法来解决,例如动态规划算法、策略迭代算法和值迭代算法。因此,我们采用强化学习( RL )方法。返回的状态被定义为折现未来回报的总和 ∑ i = t T γ i − t r ( s i , a i ) \sum_{i=t}^{T} \gamma^{i-t} r\left(s_{i}, a_{i}\right) ∑ i = t T γ i − t r ( s i , a i ) T T T γ ∈ ( 0 , 1 ) \gamma \in(0,1) γ ∈ ( 0 , 1 )
设 Q π ( s t , a t ) = E a i ∼ π [ ∑ i = t T γ i − t r ( s i , a i ) ∣ s t , a t ] Q^{\pi}\left(s_{t}, a_{t}\right)=\mathbb{E}_{a_{i} \sim \pi}\left[\sum_{i=t}^{T} \gamma^{i-t} r\left(s_{i}, a_{i}\right) \mid s_{t}, a_{t}\right] Q π ( s t , a t ) = E a i ∼ π [ ∑ i = t T γ i − t r ( s i , a i ) ∣ s t , a t ] s t s_t s t a t a_t a t
Q π ( s t , a t ) = ∑ s t + 1 , r t p ( s t + 1 , r t ∣ s t , a t ) [ r t + γ max a t + 1 Q π ( s t + 1 , a t + 1 ) ] Q^{\pi}\left(s_{t}, a_{t}\right)=\sum_{s_{t+1}, r_{t}} p\left(s_{t+1}, r_{t} \mid s_{t}, a_{t}\right)\left[r_{t}+\gamma \max _{a_{t+1}} Q^{\pi}\left(s_{t+1}, a_{t+1}\right)\right] Q π ( s t , a t ) = s t + 1 , r t ∑ p ( s t + 1 , r t ∣ s t , a t ) [ r t + γ a t + 1 max Q π ( s t + 1 , a t + 1 ) ]
Q-learning 是经典的无模型 RL 算法。 Q-learning 的本质是探索与开发,其目的是通过与环境的相互作用实现预期收益的最大化。 Q ( s t , a t ) Q(s_t, a_t) Q ( s t , a t )
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] \begin{array}{c} Q\left(s_{t}, a_{t}\right) \leftarrow Q\left(s_{t}, a_{t}\right)+\alpha\left[r_{t}+\gamma \max _{a_{t+1}} Q\left(s_{t+1}, a_{t+1}\right)\right. \left.-Q\left(s_{t}, a_{t}\right)\right] \end{array} Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ]
其中 α \alpha α
Q-learning 使用 ϵ − g r e e d y \epsilon-greedy ϵ − g r e e d y ϵ \epsilon ϵ ϵ − g r e e d y \epsilon-greedy ϵ − g r e e d y
a t = { arg max a Q ( s t , a ) , with probability 1 − ϵ , a random action, with probability ϵ . a_{t}=\left\{\begin{array}{ll} \arg \max _{a} Q\left(s_{t}, a\right), & \text { with probability } 1-\epsilon, \\ \text { a random action, } & \text { with probability } \epsilon . \end{array}\right. a t = { arg max a Q ( s t , a ) , a random action, with probability 1 − ϵ , with probability ϵ .
Q-learning 算法如Alg. 1所示。第1行是初始化。每一次迭代中,内部循环都在第4 ~ 7行进行。第5行使用公式( 15 )选择一个操作,然后在第6行执行该操作。第7行更新q值。
由于一些限制, Q-learning 不能解决我们的问题。1) Q-learning 只能解决状态空间和行为空间较小的 MDP 问题。然而,我们的问题的状态空间和行为空间是非常大的。2) Q-learning 不能处理连续的状态或动作空间。无人机的传输功率分配动作是连续的。传动功率控制在现实中是一个连续的动作。如果将输电功率分配行为离散化,用 Q-learning 方法求解,结果可能会偏离最优。3) Q-learning 使用过多的计算资源会收敛缓慢,这在我们的问题中是不实际的。因此,我们采用深度确定性策略梯度算法来解决这个问题。
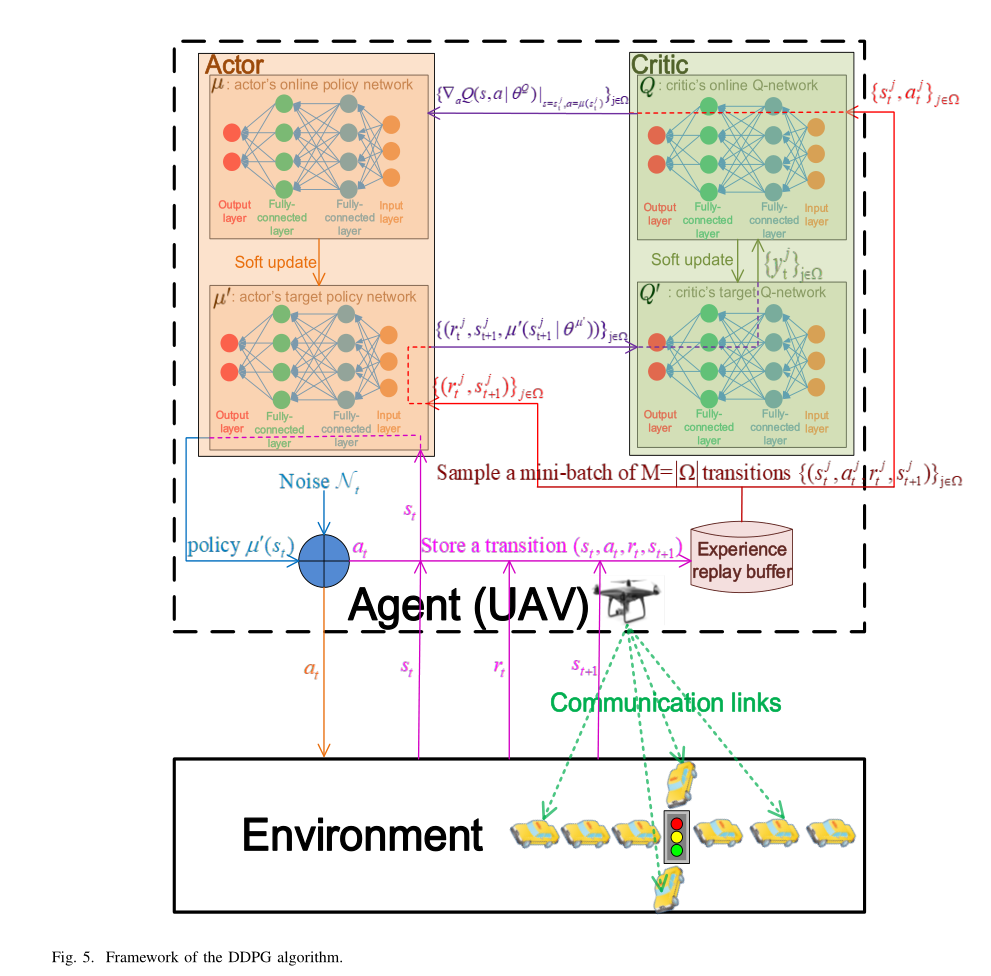
深度确定性策略梯度( DDPG )方法利用深度神经网络同时逼近行动策略 π 和值函数 Q(s, a) ,该方法有两个优点:1)采用神经网络作为逼近器,本质上是将状态和动作空间压缩到更小的潜在参数空间;2)采用梯度下降法更新网络权值,大大加快了收敛速度,减少了计算时间。从而大大节省了内存和计算资源。在现实系统中,DDPG利用了AlphaGo zero和Atari游戏中引入的强大技能,包括经验回放缓冲区( experience replay buffer )、演员评论家方法( actor-critic approach )、软更新( soft update )和探索噪音( exploration noise )。
1)经验回放缓冲区( experience replay buffer ) R b R_b R b ( s t , a t , r t , s t + 1 ) \left(s_{t}, a_{t}, r_{t}, s_{t+1}\right) ( s t , a t , r t , s t + 1 ) R b R_b R b M = ∣ Ω ∣ M = | \Omega | M = ∣ Ω ∣ { ( s j , a j , r j , s j ) } j ∈ Ω \left\{\left(s^{j}, a^{j}, r^{j}, s^{j}\right)\right\}_{j \in \Omega} { ( s j , a j , r j , s j ) } j ∈ Ω Ω \Omega Ω R b R_b R b
**2)演员-评论家方法 **Actor-critic approach:评论家近似 Q value ,演员近似动作策略。该评价方法有两个神经网络:带参数 θ Q θ^Q θ Q Q Q Q θ Q ′ θ^{Q^\prime} θ Q ′ Q ′ Q^\prime Q ′ θ μ \theta^\mu θ μ μ \mu μ θ μ ′ θ^{\mu^\prime} θ μ ′ μ ′ \mu^\prime μ ′
3)软更新 Soft update 为了提高学习的稳定性,使用较低的学习速率 τ ≪ 1 \tau \ll 1 τ ≪ 1 Q ′ Q^\prime Q ′ μ ′ \mu^\prime μ ′
θ Q ′ ← τ θ Q + ( 1 − τ ) θ Q ′ = θ Q ′ + τ ( θ Q − θ Q ′ ) θ μ ′ ← τ θ μ + ( 1 − τ ) θ μ ′ = θ μ ′ + τ ( θ μ − θ μ ′ ) \begin{array}{l} \theta^{Q^{\prime}} \leftarrow \tau \theta^{Q}+(1-\tau) \theta^{Q^{\prime}}=\theta^{Q^{\prime}}+\tau\left(\theta^{Q}-\theta^{Q^{\prime}}\right) \\ \theta^{\mu^{\prime}} \leftarrow \tau \theta^{\mu}+(1-\tau) \theta^{\mu^{\prime}}=\theta^{\mu^{\prime}}+\tau\left(\theta^{\mu}-\theta^{\mu^{\prime}}\right) \end{array} θ Q ′ ← τ θ Q + ( 1 − τ ) θ Q ′ = θ Q ′ + τ ( θ Q − θ Q ′ ) θ μ ′ ← τ θ μ + ( 1 − τ ) θ μ ′ = θ μ ′ + τ ( θ μ − θ μ ′ )
4)探测噪声 Exploration noise 在行动者的目标策略中加入探测噪声,输出一个新的动作:
a t = μ ′ ( s t ∣ θ μ ′ ) + N t a_{t}=\mu^{\prime}\left(s_{t} \mid \theta^{\mu^{\prime}}\right)+\mathcal{N}_{t} a t = μ ′ ( s t ∣ θ μ ′ ) + N t
在探索和开发之间存在一种权衡,而探索是独立于学习过程的。在式( 18 )中加入探测噪声,既保证了无人机在现有策略 μ ′ ( s t ∣ θ μ ′ ) \mu^{\prime}\left(s_{t} \mid \theta^{\mu^{\prime}}\right) μ ′ ( s t ∣ θ μ ′ )
UAV 有两个传输控制,功率和通道。我们使用功率分配作为主要的控制目标有两个原因。1)在 OFDMA 中,一旦确定了功率分配,就很容易得到信道分配。根据文献[ 40 ]的定理 4 ,在 OFDMA 中,如果所有链路的权值都与我们的奖励函数( 5 )相同,则发送端应该在每个时隙中向信道最强的接收端发送消息。在我们的问题中,由于信道状态( LoS 或 NLoS )是一个随机过程,因此不能确定最强信道。 DDPG 倾向于将更多的权力分配给概率较大的最强的渠道,因此,根据权力分配行为很容易获得渠道分配。2)功率分配是连续的, DDPG 适合处理这些动作。然而,如果使用 DDPG 进行信道分配,由于信道分配是离散的,尤其是在高峰时段,信道的数量通常很大(如 200 个),因此动作变量的数量会非常大,收敛速度也会非常慢。我们选择功率控制或飞行作为控制目标,因为控制功率和飞行比控制通道更有效。在 OFDMA 中进行功率分配,可以间接得到最佳的信道分配策略。基于以上分析,我们提出了三种算法:
功率控制 PowerControl :无人机利用 actor 网络在固定的三维位置调整传输功率分配,每个时隙的信道由算法 Alg.2 分配给车辆。 飞行控制 FlightControl :无人机利用 actor 网络调整 3D 飞行,传输功率和信道分配在每个时点平均分配给每个车辆。 联合控制 JointControl :无人机利用 actor 网络调整其三维飞行和传输功率分配,每个时隙的信道由算法 Alg.2 分配给车辆。 为了在块之间分配通道,我们引入一个变量,表示在块 i 中车辆的平均分配功率:
ρ ˉ t i = { ρ t i n t i , if n t i ≠ 0 0 , otherwise \bar{\rho}_{t}^{i}=\left\{\begin{array}{ll} \frac{\rho_{t}^{i}}{n_{t}^{i}}, & \text { if } n_{t}^{i} \neq 0 \\ 0, & \text { otherwise } \end{array}\right. ρ ˉ t i = { n t i ρ t i , 0 , if n t i = 0 otherwise
信道分配算法如 Alg. 2 所示,它是在获得功率分配动作后执行的。如上所述,当功率分配已知时, OFDMA 中实现了最佳的信道分配。第 1 行是初始化。行 2 ~ 3 计算和排序 $ \overline{\boldsymbol{\rho}}{t}= \left{\bar{\rho} {t}^{i}\right}_{i \in{0,1,2,3,4}} $ 。第 5 行将最大通道数分配给当前可能最强的通道,第 6 行更新剩余的通道总数。给出了基于 DDPG 的算法。
在 Alg. 3 中给出了基于 DDPG 的算法。该算法有两部分:初始化和主进程。首先,我们在第 1 ~ 3 行描述初始化。在第 1 行,所有状态都初始化:红绿灯 L 是初始化为 0 ,所有块的汽车的数量 n 是 0 ,无人机的块和高度是随机的,和第 i 块的信道状态 H i H^i H i R b R_b R b
其次,介绍了主要流程。第 5 行初始化一个随机过程以进行操作探索。第 6 行接收初始状态 s 1 s_1 s 1 a ˉ t \bar{a}_{t} a ˉ t N t N_t N t a t a_t a t a ˉ t \bar{a}_{t} a ˉ t a t a_t a t a ˉ t \bar{a}_{t} a ˉ t a t a_t a t R b R_b R b R b R_b R b y j y^j y j
Alg. 3 中基于 DDPG 的算法本质上是 Alg. 1 中的近似 Q-learning 方法。第 8 行中的探测噪声近似于 Q-learning 中公式( 15 )的第二种情况。 Alg. 3 的第 18 ~ 19 行使 [ r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] \left[r_{t}+\gamma \max _{a_{t+1}} Q\left(s_{t+1}, a_{t+1}\right)-Q\left(s_{t}, a_{t}\right)\right] [ r t + γ max a t + 1 Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ]
Alg. 3 的第 20 行近似于 Q-learning 中公式( 15 )的第一个情况,因为它们都是为了获得最大 q 值的策略。在 Q-learning 中, Alg. 3 第 21 行 Q ′ Q^\prime Q ′ τ \tau τ α \alpha α
1) 在训练阶段,我们训练演员和批评家,并存储他们的神经网络参数。图 5 显示了数据流和参数更新过程。训练阶段分为两部分。首先,通过从体验回放缓冲区 R b R_b R b Q ′ Q^\prime Q ′ μ ′ \mu^\prime μ ′
训练流程如下:从 R b R_b R b { ( s t j , a t j , r t j , s t + 1 j ) } j ∈ Ω \left\{\left(s_{t}^{j}, a_{t}^{j}, r_{t}^{j}, s_{t+1}^{j}\right)\right\}_{j \in \Omega} { ( s t j , a t j , r t j , s t + 1 j ) } j ∈ Ω Ω \Omega Ω ∣ Ω ∣ = M |\Omega| = M ∣ Ω ∣ = M R b R_b R b R b R_b R b { r t j , s t + 1 j } j ∈ Ω → μ ′ \left\{r_{t}^{j}, s_{t+1}^{j}\right\}_{j \in \Omega} \rightarrow \mu^{\prime} { r t j , s t + 1 j } j ∈ Ω → μ ′ { s t j , a t j } j ∈ Ω → Q \left\{s_{t}^{j}, a_{t}^{j}\right\}_{j \in \Omega} \rightarrow Q { s t j , a t j } j ∈ Ω → Q μ ′ \mu^\prime μ ′ { r t j , s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) } j ∈ Ω \left\{r_{t}^{j}, s_{t+1}^{j}, \mu^{\prime}\left(s_{t+1}^{j} \mid \theta^{\mu^{\prime}}\right)\right\}_{j \in \Omega} { r t j , s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) } j ∈ Ω Q ′ Q^\prime Q ′ { y t j } j ∈ Ω \{y_t^j\}_{j \in \Omega} { y t j } j ∈ Ω { ∇ a Q ( s , a ∣ θ Q ) ∣ s = s t j , a = μ ( s t j ) } j ∈ Ω \left\{\left.\nabla_{a} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=s_{t}^{j}, a=\mu\left(s_{t}^{j}\right)}\right\}_{j \in \Omega} { ∇ a Q ( s , a ∣ θ Q ) ∣ ∣ ∣ s = s t j , a = μ ( s t j ) } j ∈ Ω μ \mu μ Q ′ Q^\prime Q ′ μ ′ \mu^\prime μ ′
批评家的目标Q-网络 Q ′ Q^\prime Q ′ Q Q Q Q ′ Q^\prime Q ′ { ( r t j , s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) ) } j ∈ Ω \left\{\left(r_{t}^{j}, s_{t+1}^{j}, \mu^{\prime}\left(s_{t+1}^{j} \mid \theta^{\mu^{\prime}}\right)\right)\right\}_{j \in \Omega} { ( r t j , s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) ) } j ∈ Ω { y t j } j ∈ Ω \{y_t^j\}_{j \in \Omega} { y t j } j ∈ Ω Q Q Q y t j y_t^j y t j
y t j = r t j + γ Q ′ ( s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) ∣ θ Q ′ ) y_{t}^{j}=r_{t}^{j}+\gamma Q^{\prime}\left(s_{t+1}^{j}, \mu^{\prime}\left(s_{t+1}^{j} \mid \theta^{\mu^{\prime}}\right) \mid \theta^{Q^{\prime}}\right) y t j = r t j + γ Q ′ ( s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) ∣ θ Q ′ )
Q Q Q { { s t j , a t j } j ∈ Ω , } \left\{\left\{s_{t}^{j}, a_{t}^{j}\right\}_{j \in \Omega},\right\} { { s t j , a t j } j ∈ Ω , } { ∇ a Q ( s , a ∣ θ Q ) ∣ s = s ∗ j , a = μ ( s t j ) } j ∈ Ω \left\{\left.\nabla_{a} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=s_{*}^{j}, a=\mu\left(s_{t}^{j}\right)}\right\}_{j \in \Omega} { ∇ a Q ( s , a ∣ θ Q ) ∣ ∣ ∣ s = s ∗ j , a = μ ( s t j ) } j ∈ Ω { s t j } j ∈ Ω \{s_{t}^{j}\}_{j\in \Omega} { s t j } j ∈ Ω R b R_b R b μ ( s t j ) = arg max a Q ( s t j , a ) \mu\left(s_{t}^{j}\right)=\arg \max _{a} Q\left(s_{t}^{j}, a\right) μ ( s t j ) = arg max a Q ( s t j , a )
演员在线策略网络 µ 和目标策略网络 μ ′ \mu^\prime μ ′ { ∇ a Q ( s , a ∣ θ Q ) ∣ s = s t j , a = μ ( s t j ) } j ∈ Ω \left\{\left.\nabla_{a} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=s_{t}^{j}, a=\mu\left(s_{t}^{j}\right)}\right\}_{j \in \Omega} { ∇ a Q ( s , a ∣ θ Q ) ∣ ∣ ∣ s = s t j , a = μ ( s t j ) } j ∈ Ω μ ′ \mu^\prime μ ′ { r t j , s t + 1 j } j ∈ Ω \{r^j_t, s^j_{t+1}\}_{j\in \Omega} { r t j , s t + 1 j } j ∈ Ω { r t j , s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) } j ∈ Ω \left\{r_{t}^{j}, s_{t+1}^{j}, \mu^{\prime}\left(s_{t+1}^{j} \mid \theta^{\mu^{\prime}}\right)\right\}_{j \in \Omega} { r t j , s t + 1 j , μ ′ ( s t + 1 j ∣ θ μ ′ ) } j ∈ Ω Q ′ Q^\prime Q ′ { y t j } j ∈ Ω \{y_t^j\}_{j \in \Omega} { y t j } j ∈ Ω { r t j , s t + 1 j } j ∈ Ω \{r^j_t, s^j_{t+1}\}_{j\in \Omega} { r t j , s t + 1 j } j ∈ Ω R b R_b R b
四种神经网络( Q Q Q Q ′ Q^\prime Q ′ μ \mu μ μ ′ \mu^\prime μ ′ L o s s ( θ Q ) Loss (\theta^Q) L o s s ( θ Q ) y t j y_t^j y t j
∇ θ Q Loss t ( θ Q ) = ∇ θ Q [ 1 M ∑ j = 1 M ( y t j − Q ( s t j , a t j ∣ θ Q ) ) 2 ] \nabla_{\theta^{Q}} \operatorname{Loss}_{t}\left(\theta^{Q}\right)=\nabla_{\theta^{Q}}\left[\frac{1}{M} \sum_{j=1}^{M}\left(y_{t}^{j}-Q\left(s_{t}^{j}, a_{t}^{j} \mid \theta^{Q}\right)\right)^{2}\right] ∇ θ Q L o s s t ( θ Q ) = ∇ θ Q [ M 1 j = 1 ∑ M ( y t j − Q ( s t j , a t j ∣ θ Q ) ) 2 ]
目标Q -网络 Q ′ Q^\prime Q ′ θ Q ′ θ^{Q^\prime} θ Q ′ μ \mu μ θ μ θ^\mu θ μ
E s t [ ∇ θ μ Q ( s , a ∣ θ Q ) ∣ s = s t , a = μ ( s t ∣ θ μ ) ] = E s t [ ∇ a Q ( s , a ∣ θ Q ) ∣ s = s t , a = μ ( s t ) ∇ θ μ μ ( s ∣ θ μ ) ∣ s = s t ] \mathbb{E}_{s_{t}}\left[\left.\nabla_{\theta^{\mu}} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=s_{t}, a=\mu\left(s_{t} \mid \theta^{\mu}\right)}\right] =\mathbb{E}_{s_{t}}\left[\left.\left.\nabla_{a} Q\left(s, a \mid \theta^{Q}\right)\right|_{s=s_{t}, a=\mu\left(s_{t}\right)} \nabla_{\theta^{\mu}} \mu\left(s \mid \theta^{\mu}\right)\right|_{s=s_{t}}\right] E s t [ ∇ θ μ Q ( s , a ∣ θ Q ) ∣ ∣ ∣ s = s t , a = μ ( s t ∣ θ μ ) ] = E s t [ ∇ a Q ( s , a ∣ θ Q ) ∣ ∣ ∣ s = s t , a = μ ( s t ) ∇ θ μ μ ( s ∣ θ μ ) ∣ ∣ ∣ ∣ s = s t ]
目标政策网络 μ ′ \mu^\prime μ ′ θ μ ′ \theta^{\mu^\prime} θ μ ′
在每个时隙 t ,将环境中的当前状态 s t s_t s t μ ′ \mu^\prime μ ′ μ ′ \mu^\prime μ ′ μ ′ ( s t ) ∣ θ μ ′ \mu^{\prime}\left(s_{t}\right) \mid \theta^{\mu^{\prime}} μ ′ ( s t ) ∣ θ μ ′ {\mu {\prime}}\right) $ 上加入探测噪声 N ,得到无人机在公式( 18 )处的动作。
2) 在测试阶段,根据所存储的参数恢复演员目标策略网络的神经网络 μ ′ \mu^\prime μ ′ R b R_b R b s t s_t s t μ ′ \mu^\prime μ ′ μ ′ ( s t ∣ θ μ ′ ) \mu^\prime(s_t \mid \theta^{\mu^\prime}) μ ′ ( s t ∣ θ μ ′ ) μ ′ ( s t ∣ θ μ ′ ) \mu^\prime(s_t \mid \theta^{\mu^\prime}) μ ′ ( s t ∣ θ μ ′ ) μ ′ \mu^\prime μ ′ μ ′ ( s t ∣ θ μ ′ ) \mu^\prime(s_t \mid \theta^{\mu^\prime}) μ ′ ( s t ∣ θ μ ′ )
无人机的能量主要用于通信和三维飞行两部分。上述 Alg. 3 中提出的解决方案没有考虑 3Dflight 的能耗。在本小节中,我们将讨论如何将三维飞行的能量消耗纳入算法。为了鼓励或抑制无人机在不同能量消耗下不同方向的三维飞行动作,我们对奖励函数和 DDPG 框架进行了修改。
无人机的目标是最大限度地提高每能量单位的总吞吐量,因为无人机的电池容量有限。例如,无人机大疆 Mavic Air 满载时只能飞行 21 分钟。考虑到无人机三维飞行的能量消耗远大于通信的能量消耗,我们只使用前者作为总能量消耗。因此,将奖励函数( 5 )修改为
r ˉ ( s t , a t ) = 1 e ( a t ) ∑ i ∈ { 0 , 1 , 2 , 3 , 4 } b n t i c t i log ( 1 + ρ t i h t i b c t i σ 2 ) \bar{r}\left(s_{t}, a_{t}\right)=\frac{1}{e\left(a_{t}\right)} \sum_{i \in\{0,1,2,3,4\}} b n_{t}^{i} c_{t}^{i} \log \left(1+\frac{\rho_{t}^{i} h_{t}^{i}}{b c_{t}^{i} \sigma^{2}}\right) r ˉ ( s t , a t ) = e ( a t ) 1 i ∈ { 0 , 1 , 2 , 3 , 4 } ∑ b n t i c t i log ( 1 + b c t i σ 2 ρ t i h t i )
其中, e ( a t ) e(a_t) e ( a t ) e ( a t ) e(a_t) e ( a t )
e ( a t ) = { 1 270 E f u l l , if moving downward 5 meters 1 210 E f u l l , if moving horizontally 1 170 E f u l l , if moving upward 5 meters e\left(a_{t}\right)=\left\{\begin{array}{ll} \frac{1}{270} E_{\mathrm{full}}, & \text { if moving downward } 5 \text { meters } \\ \frac{1}{210} E_{\mathrm{full}}, & \text { if moving horizontally } \\ \frac{1}{170} E_{\mathrm{full}}, & \text { if moving upward } 5 \text { meters } \end{array}\right. e ( a t ) = ⎩ ⎪ ⎨ ⎪ ⎧ 2 7 0 1 E f u l l , 2 1 0 1 E f u l l , 1 7 0 1 E f u l l , if moving downward 5 meters if moving horizontally if moving upward 5 meters
其中 E f u l l E_{\mathrm{full}} E f u l l δ ( t ) \delta(t) δ ( t )
δ ( t ) = r ˉ ( s t , a t ) − Q ( s t , a t ) \delta(t)=\bar{r}\left(s_{t}, a_{t}\right)-Q\left(s_{t}, a_{t}\right) δ ( t ) = r ˉ ( s t , a t ) − Q ( s t , a t )
其中, δ ( t ) \delta(t) δ ( t ) r ˉ ( s t , a t ) \bar{r}\left(s_{t}, a_{t}\right) r ˉ ( s t , a t ) Q ( s t , a t ) Q\left(s_{t}, a_{t}\right) Q ( s t , a t ) δ ( t ) \delta(t) δ ( t )
Q ( s t , a t ) ← Q ( s t , a t ) + α δ ( t ) ⇔ Q ( s t , a t ) ← Q ( s t , a t ) + α ( r ˉ ( s t , a t ) − Q ( s t , a t ) ) , \begin{array}{l} Q\left(s_{t}, a_{t}\right) \leftarrow Q\left(s_{t}, a_{t}\right)+\alpha \delta(t) \Leftrightarrow \\ Q\left(s_{t}, a_{t}\right) \leftarrow Q\left(s_{t}, a_{t}\right)+\alpha\left(\bar{r}\left(s_{t}, a_{t}\right)-Q\left(s_{t}, a_{t}\right)\right), \end{array} Q ( s t , a t ) ← Q ( s t , a t ) + α δ ( t ) ⇔ Q ( s t , a t ) ← Q ( s t , a t ) + α ( r ˉ ( s t , a t ) − Q ( s t , a t ) ) ,
其中, α α α
引入 α + \alpha^+ α + α − \alpha^- α − δ ( t ) ≥ 0 \delta(t) \ge 0 δ ( t ) ≥ 0 δ ( t ) < 0 \delta(t) \lt 0 δ ( t ) < 0 α + \alpha^+ α + α − \alpha^- α −
Q ( s t , a t ) ← Q ( s t , a t ) + { α + δ ( t ) , if δ ( t ) ≥ 0 α − δ ( t ) , if δ ( t ) < 0 Q\left(s_{t}, a_{t}\right) \leftarrow Q\left(s_{t}, a_{t}\right)+\left\{\begin{array}{l} \alpha^{+} \delta(t), \text { if } \delta(t) \geq 0 \\ \alpha^{-} \delta(t), \text { if } \delta(t)<0 \end{array}\right. Q ( s t , a t ) ← Q ( s t , a t ) + { α + δ ( t ) , if δ ( t ) ≥ 0 α − δ ( t ) , if δ ( t ) < 0
我们将预测误差 δ ( t ) \delta(t) δ ( t )
δ ( t ) = r ˉ ( s t , a t ) − Q ( s t , a t ∣ θ Q ) \delta(t)=\bar{r}\left(s_{t}, a_{t}\right)-Q\left(s_{t}, a_{t} \mid \theta^{Q}\right) δ ( t ) = r ˉ ( s t , a t ) − Q ( s t , a t ∣ θ Q )
我们分别用 τ + \tau^+ τ + τ − \tau^- τ − δ ( t ) ≥ 0 \delta(t) \ge 0 δ ( t ) ≥ 0 δ ( t ) < 0 \delta(t) \lt 0 δ ( t ) < 0 Q ′ Q^\prime Q ′
θ Q ′ ← { τ + θ Q + ( 1 − τ + ) θ Q ′ , if δ ( t ) ≥ 0 τ − θ Q + ( 1 − τ − ) θ Q ′ , if δ ( t ) < 0 \theta^{Q^{\prime}} \leftarrow\left\{\begin{array}{ll} \tau^{+} \theta^{Q}+\left(1-\tau^{+}\right) \theta^{Q^{\prime}}, & \text { if } \delta(t) \geq 0 \\ \tau^{-} \theta^{Q}+\left(1-\tau^{-}\right) \theta^{Q^{\prime}}, & \text { if } \delta(t)<0 \end{array}\right. θ Q ′ ← { τ + θ Q + ( 1 − τ + ) θ Q ′ , τ − θ Q + ( 1 − τ − ) θ Q ′ , if δ ( t ) ≥ 0 if δ ( t ) < 0
演员目标策略网络 µ ′ µ^\prime µ ′
θ μ ′ ← { τ + θ μ + ( 1 − τ + ) θ μ ′ , if δ ( t ) ≥ 0 τ − θ μ + ( 1 − τ − ) θ μ ′ , if δ ( t ) < 0 \theta^{\mu^{\prime}} \leftarrow\left\{\begin{array}{l} \tau^{+} \theta^{\mu}+\left(1-\tau^{+}\right) \theta^{\mu^{\prime}}, \text { if } \delta(t) \geq 0 \\ \tau^{-} \theta^{\mu}+\left(1-\tau^{-}\right) \theta^{\mu^{\prime}}, \text { if } \delta(t)<0 \end{array}\right. θ μ ′ ← { τ + θ μ + ( 1 − τ + ) θ μ ′ , if δ ( t ) ≥ 0 τ − θ μ + ( 1 − τ − ) θ μ ′ , if δ ( t ) < 0
当 τ + > τ − \tau^+ \gt \tau^- τ + > τ − τ + < τ − \tau^+ \lt \tau^- τ + < τ − y ˉ t j \bar{y}^j_t y ˉ t j
∇ θ Q Loss t ( θ Q ) = ∇ θ Q [ 1 M ∑ j = 1 M ( y ˉ t j − Q ( s t j , a t j ∣ θ Q ) ) 2 ] \nabla_{\theta^{Q}} \operatorname{Loss}_{t}\left(\theta^{Q}\right)=\nabla_{\theta^{Q}}\left[\frac{1}{M} \sum_{j=1}^{M}\left(\bar{y}_{t}^{j}-Q\left(s_{t}^{j}, a_{t}^{j} \mid \theta^{Q}\right)\right)^{2}\right] ∇ θ Q L o s s t ( θ Q ) = ∇ θ Q [ M 1 j = 1 ∑ M ( y ˉ t j − Q ( s t j , a t j ∣ θ Q ) ) 2 ]
式中, y ˉ t j = r ˉ t j \bar{y}_{t}^{j} = \bar{r}^j_t y ˉ t j = r ˉ t j
考虑到 3D 飞行的能耗,我们对 MDP 、 DDPG 框架和基于 DDPG 的算法进行了修改:
1.MDP 修改如下。状态空间 S = (L, x, z, n, H, E),其中 E 为无人机电池的能量。能量的变化如下
E t + 1 = max { E t − e ( a t ) , 0 } E_{t+1}=\max \left\{E_{t}-e\left(a_{t}\right), 0\right\} E t + 1 = max { E t − e ( a t ) , 0 }
MDP 制定和状态转换的其他部分与第 3- C 节相同。
2.DDPG 框架中有三处修改:a) 评论者的目标 Q-network Q ′ Q^\prime Q ′ y ˉ j = r ˉ j \bar{y}^j = \bar{r}^j y ˉ j = r ˉ j y j y^j y j Q ′ Q^\prime Q ′ μ ′ \mu^\prime μ ′
3.基于 DDPG 的算法是在 Alg. 3 的基础上改进的。在每一集的开始,初始化无人机的能量状态为满。在一个训练步骤的每一个时间步中,能量状态更新为公式( 32 ),当能量状态 E t ≤ 0 E_t \le 0 E t ≤ 0
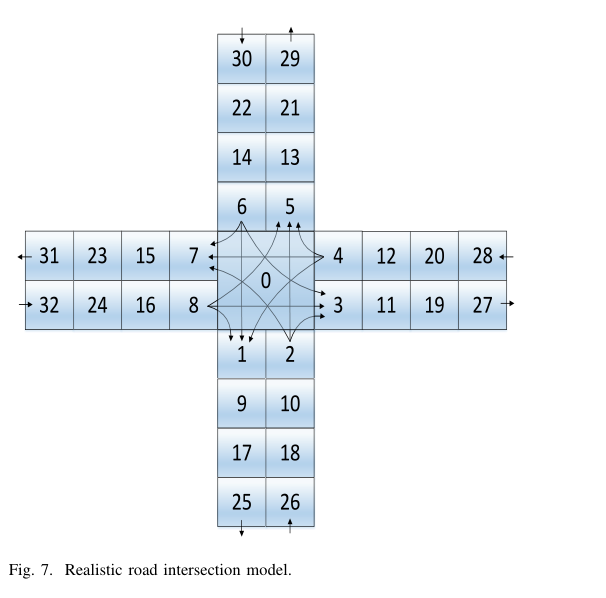
对于图 2 中的单向双流交叉口,我们提出了深度强化学习算法的最优性验证。然后,我们研究一个更真实的路口,如图 7 所示,并给出我们的仿真结果。
我们的模拟是在一台装有 Linux 操作系统、 200 GB 内存、两台 Intel® Xeon® Gold 5118 CPUs@2.30 GHz 、特斯拉 v100r001 pcie GPU 的服务器上执行的。
Alg. 3 的实现包括两个部分:为我们的场景构建环境(包括流量和通信模型),以及使用 TensorFlow 中的 DDPG 算法。
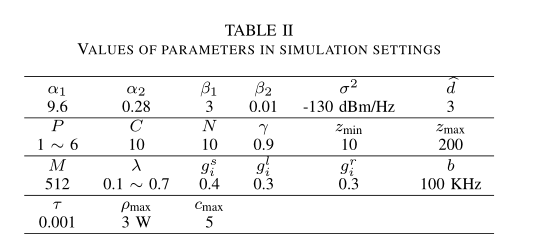
参数设置概述见表 2 。在仿真中,有三种类型的参数: DDPG 算法参数、通信参数和无人机/车辆参数。
首先,描述了 DDPG 算法的参数。训练步骤的数量是 256 次,每步的时间段是 256 个,所以总时间段的数量是 65,536 个。经验重放缓冲区容量为 10,000 ,目标网络的学习速率 τ \tau τ
其次,我们描述了通信参数。 α 1 \alpha_1 α 1 α 2 \alpha_2 α 2 σ 2 \sigma^2 σ 2 ρ m a x \rho_{max} ρ m a x c m a x c_{max} c m a x
第三,描述无人机/车辆参数。 λ 被设定为 0.1 ~ 0.7 。路障 d ^ \hat{d} d ^ d ^ \hat{d} d ^ d ^ \hat{d} d ^ γ \gamma γ
图 2 中简化场景的假设如下:为了使状态空间较小,便于验证,我们假设所有通信链路的信道状态为 LoS ,无人机高度固定为 150 米,无人机只能调整其水平飞行控制和发射控制。交通灯状态假定有两个值(红色或绿色)。
在提出的解决方案中,神经网络的配置是基于 DDPG 动作空间的配置。神经网络由输入层、全连接层和输出层组成。 actor 中完全连接的层数设置为 4 。
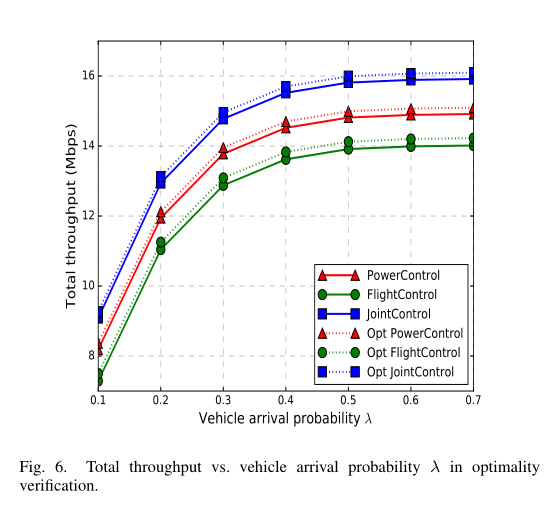
理论上,深度强化学习算法(包括 DDPG 算法)解决了 MDP 问题,以更少的内存和计算资源实现了最优结果。我们提供了 Alg. 3 中基于 DDPG 的算法在图 2 中单向两流交叉口的最优性验证。原因如下: (1) 这种简化场景下的 MDP 问题被明确定义,使用 Python MDP 工具箱可以得到理论上的最优策略; (ii) 在我们将 TensorFlow 中的 DDPG 算法应用到图 7 中更加真实的交叉口场景之前,这个最优性验证过程也为我们提供了一个很好的代码调试过程。
基于 DDPG 的算法的结果与使用 Python MDP Toolbox 的策略迭代算法的结果匹配(作为最优策略)。策略迭代算法和基于 DDPG 的算法得到的总吞吐量如图 6 中的虚线和实线所示。因此,基于 DDPG 的算法可以获得接近最优的策略。我们看到, JointControl 中的总吞吐量是最大的,远远高于 PowerControl 和 FlightControl 。这与我们认为的权力和飞行分配的联合控制比两者的控制都好是一致的。 PowerControl 的性能优于 FlightControl 。在所有算法中,吞吐量随着车辆到达概率 λ 的增大而增大,当 λ≥0.6 时,由于交通拥堵导致吞吐量饱和。
我们在图 7 中考虑一个更现实的交叉口模型。共有 33 个街区,有 4 个入口 (26、28、30、32街区) 和 4 个出口(25、27、29、31街区)。块 i ∈ { 2 , 4 , 6 , 8 } i \in \{2,4,6,8\} i ∈ { 2 , 4 , 6 , 8 } g i s g^s_i g i s g i l g^l_i g i l g i r g^r_i g i r g i s + g i l + g i r = 1 g^s_i+ g^l_i + g^r_i = 1 g i s + g i l + g i r = 1
现在,我们描述与上一小节不同的设置。折现因子 γ \gamma γ ρ m a x \rho_{max} ρ m a x c m a x c_{max} c m a x ( g i s 、 g i l 、 g i r ) (g^s_i、g^l_i、g^r_i) ( g i s 、 g i l 、 g i r )
无人机的水平和垂直飞行动作如下。我们假设无人机的块为 0 ~ 8 ,因为在交叉口 block 0 的车辆数量通常是最大的,并且无人机不会移动到离交叉口的块较远的块。此外,在一个时间段内,我们假设无人机可以停留或只移动到其相邻的街区。无人机的垂直飞行动作由公式( 6 )设置, PowerControl 中无人机停留在 0 块,高度为 150 米。
我们比较了两个基线方案。为了保证通信系统的公平性,通常采用传输功率和信道分配相等的方法。因此,它们被用于基线方案。
第一个基线方案为 Cycle ,即无人机在固定高度(如 150 米)逆时针循环,无人机在每个时隙平均分配给每个车辆的传输功率和信道。无人机在不考虑车流的情况下,周期性地沿固定轨迹运动。
第二个基线方案为 Greedy ,即在固定高度(如 150 米),无人机贪婪地移动到车辆数量最大的块上。如果一个不相邻的块拥有最多的车辆,则无人机必须移动到 0 块,然后移动到该块。无人机还在每个时隙内将传输功率和信道平均分配给每个车辆。无人机试图通过靠近车辆数量最多的街区来服务。
训练时间约为 4 小时,测试时间几乎是实时的,因为它只使用了训练良好的目标策略网络。接下来,我们首先展示了损失函数的收敛性,然后展示了总吞吐量与折扣因子、总传输功率、总信道数和车辆到达概率之间的关系,最后给出了三维飞行时的总吞吐量和无人机飞行时间与能量百分比之间的关系。
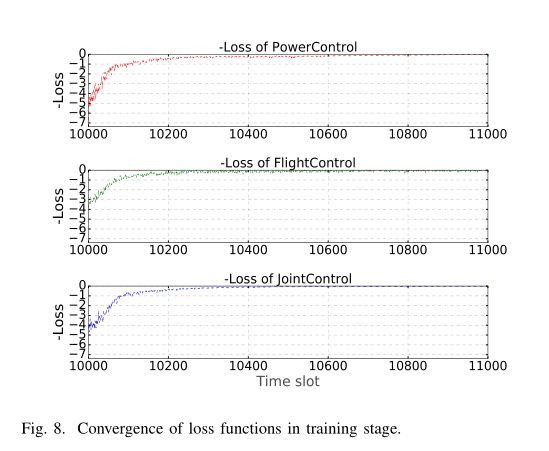
PowerControl、FlightControl 和 JointControl 训练阶段损耗函数的收敛性表明,该神经网络训练良好。如图 8 所示, P = 6, C = 200,λ = 0.5, γ = 0.9 ,时间段为 10000 ~ 11000 。前 10,000 个时隙没有显示出来,因为在 0 ~ 10,000 个时隙期间,体验回放缓冲区还没有达到它的容量。我们可以看到,三种算法的损失函数都收敛于时隙 11000 之后。本文中的其他指标默认在测试阶段进行测量。
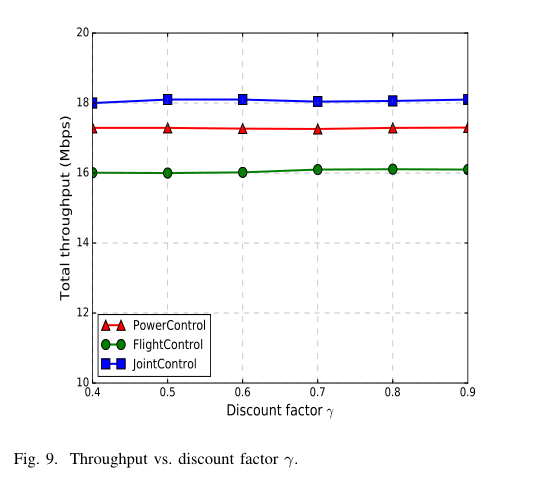
当 P = 6, C = 200, λ = 0.5 时,总吞吐量与折扣因子 γ \gamma γ γ \gamma γ
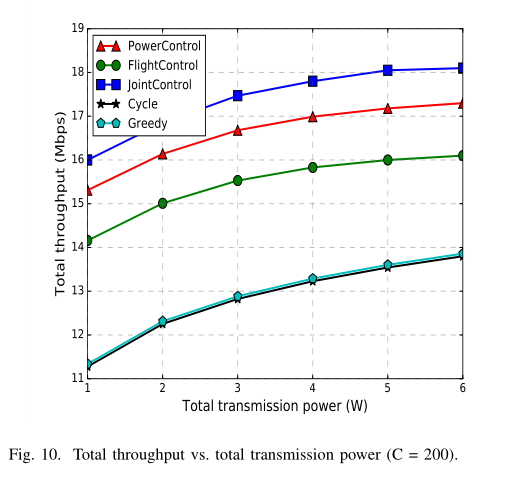
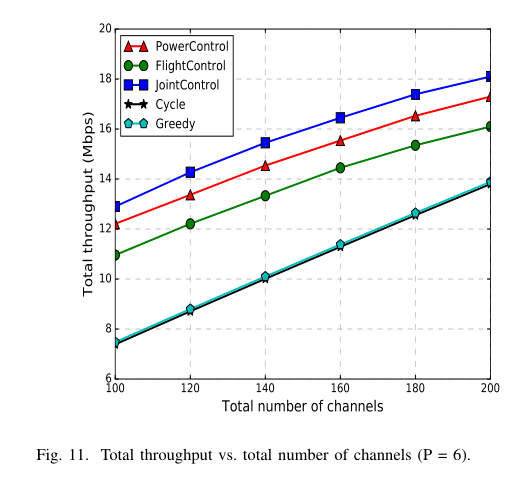
总吞吐量与总传输功率 (P = 1 ~ 6) 和总信道数 (C = 100 ~ 200) 的关系如图 10 和图 11 所示,其中设 λ = 0.5, γ = 0.9 。我们看到, JointControl 分别在不同的传输功率和信道预算下实现了最好的性能。当总传输功率或总信道数增加时,所有算法的总吞吐量都增加。 PowerControl 和 FlightControl 只对传输功率或 3Dflight 进行调节,而 JointControl 对两者进行共同调节,所以性能最好。与 Cycle 和 Greedy 算法相比,基于 DDPG 的算法的总吞吐量有很大的提高。 Greedy 的表现比 Cycle 稍微好一点,因为 Greedy 会尽量靠近拥有最多车辆的区块。
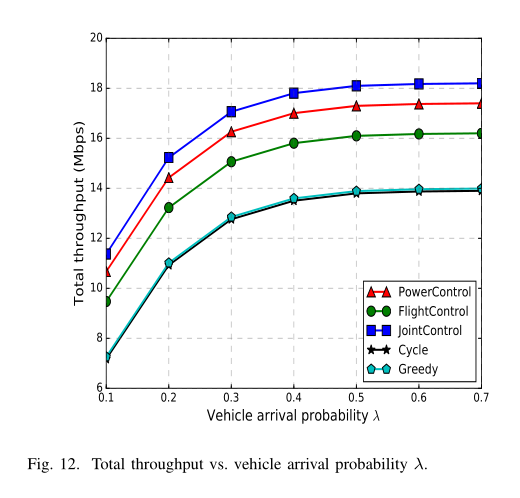
总吞吐量与车辆到达概率 λ 的关系如图 12 所示。需要注意的是,交叉口的通行能力为 2 个单位,即交叉口最多可以同时服务两个车流,因此不能服务 λ 很高的车流,如 λ = 0.8 和 λ = 0.9 。我们看到,当λ增加时,即更多的车辆到达交叉口,总吞吐量增加。然而,当 λ 变高时,例如 λ = 0.6 ,由于交通拥挤,总吞吐量饱和。
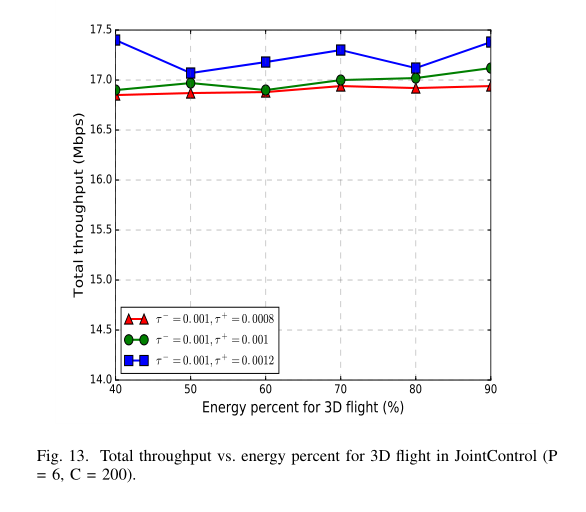
接下来,我们对考虑到 3Dflight 的能耗的指标进行测试。在 JointControl 中, 3D 飞行的总吞吐量与能量百分比如图 13 所示。当 τ + \tau^+ τ + τ + \tau^+ τ +
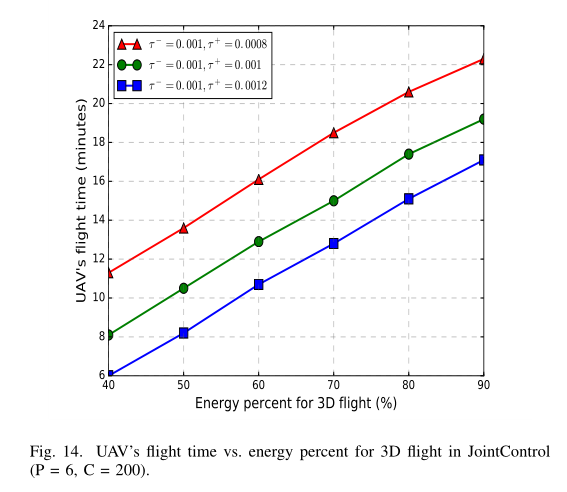
图 14 所示为三维飞行中无人机的飞行时间与能量百分比。当 τ − = 0.001 \tau^−= 0.001 τ − = 0 . 0 0 1 τ + = 0.0008 \tau^+ = 0.0008 τ + = 0 . 0 0 0 8 τ − = 0.001 \tau^−= 0.001 τ − = 0 . 0 0 1 τ + = 0.0012 \tau^+= 0.0012 τ + = 0 . 0 0 1 2 τ − = τ + = 0.001 \tau^−=\tau^+ = 0.001 τ − = τ + = 0 . 0 0 1
我们研究了一个无人机辅助的车辆网络,其中无人机作为一个中继,以最大化无人机和车辆之间的总吞吐量。我们重点研究了无人机在三维飞行下可以调整其传输控制(功率和信道)的下行通信。我们将问题表述为 MDP 问题,探讨了无人机和车辆在不同动作下的状态转换,然后提出了三种基于 DDPG 算法的深度强化学习方案,最后,通过修改奖励函数和 DDPG 框架,将其扩展到考虑无人机 3D 飞行的能耗。在一个简化的状态空间和动作空间较小的场景中,验证了基于 DDPG 的算法的最优性。通过仿真结果,我们证明了该算法在更真实的交通场景下的性能优于两种基线方案。
未来,我们将考虑多架无人机组成中继网络来辅助车辆网络的场景,并研究覆盖重叠/概率、中继选择、能量收集通信和无人机合作通信协议。我们使用服务器对提出的解决方案进行了预训练,我们希望无人机在未来可以训练神经网络,如果在边缘应用光和低能耗 GPU 的话。