无人机辅助移动边缘计算的计算卸载优化:一种深度确定性策略梯度方法(3)——基础知识
参考文献:
[1] Wang Y , Fang W , Ding Y , et al. Computation offloading optimization for UAV-assisted mobile edge computing: a deep deterministic policy gradient approach[J]. Wireless Networks, 2021:1-16.doi:https://doi.org/10.1007/s11276-021-02632-z
3 基于DDPG的计算卸载优化
在本节中,我们首先介绍MDP、Q-Learning、DQN和DDPG这些重要的新兴RL技术的基本知识。然后,讨论了如何利用DDPG来训练无人机辅助MEC系统的高效计算卸载策略。详细地定义了状态空间、动作空间和奖励函数,描述了数据预处理的状态归一化,并举例说明了训练算法和测试算法的过程。
3.1 RL介绍
3.1.1 MDP
MDP是描述离散时间随机控制过程的数学框架,在该过程中,结果是部分随机的,并且处于主体或决策者的控制下。它正式地描述了一个环境,它是完全可观察到的强化学习。通常,MDP可以定义为一个元组 (S,A,p(.,.),r) ,S 是状态空间, A 是动作空间,p(si+1∣si,ai) 是执行动作 ai∈A 从当前状态 si∈S 到下一状态 si+1∈S 的转移概率,同时 $r: \mathcal S \times \mathcal{A} \rightarrow \mathcal R $是即时/即时奖励功能。我们表示 $\pi : \mathcal S \rightarrow \mathcal P(\mathcal A) $ 作为一个“策略”,它是从一个状态映射到一个动作。MDP的目标是找到一个最优的政策,可以最大化预期的累积回报:
Ri=l=i∑∞γl−irl
其中, γ∈[0,1] 是折扣因子, rl=r(sl,al) 是第 l 个时间段的即时奖励。在策略 π 下,状态 si 的预期折现收益定义为状态值函数,即
Vπ(si)=Eπ[Ri∣si]
同样,在策略 π 下,si 状态下采取行动 ai后的预期折现收益定义为一个行动值函数,即:
Qπ(si)=Eπ[Ri∣si,ai]
根据Bellman方程,状态值函数和动作值函数的递归关系分别表示为:
Vπ(si)=Eπ[r(si,ai)+γVπ(si+1)]Qπ(si,ai)=Eπ[r(si,ai)+γQπ(si+1,ai+1)]
既然我们的目标是找到最优的政策 π∗ 时,可通过最优值函数求出各状态下的最优动作。最优状态值函数可以表示为:
V∗(si)=ai∈AmaxEπ[r(si,ai)+γVπ(si+1)].
最优行为值函数也遵循最优策略 π∗ ,我们可以写出 用 Q∗ 使用 V∗ 表示如下:
Q∗(si,ai)=Eπ[r(si,ai)+γV∗(si+1)]
3.1.2 Q-learning
RL是机器学习的一个重要分支,agent通过与控制环境交互,使其达到最优状态,从而获得最大的收益。虽然RL常用于解决 MDPs 的优化问题,但潜在传播概率 p(si+1∣si,ai) 是未知的,甚至是不稳定的。在RL中,agent试图通过与控制环境的交互,并通过之前的经验调整自己的行为来获得最大的回报。Q-learning 是 RL 中一种流行而有效的方法,它是一种 off-policy 时差(TD)控制算法。状态-行为函数即最优Q函数的Bellman最优方程可以表示为:
Q∗(si,ai)=Eπ[r(si,ai)+γai+1maxQ∗(si+1,ai+1)]
通过迭代过程可以找到Q函数的最优值。agent从经验元组 (si,ai,ri,si+1) 学习,Q函数可在第 i 步时间更新如下:
Q(si,ai)←Q(si,ai)+α[r(si,ai)+γai+1maxQ(si+1,ai+1)−Q(si,ai)]
其中, α 为学习率, r(si,ai)+γmaxai+1Q(si+1,ai+1) 为预测的Q值, Q(si,ai) 是当前Q值。预测Q值和当前Q值之间的差就是TD误差。当选择合适的学习速率时,Q学习算法收敛。
3.1.3 DQN
Q-learning算法通过维护一个查询表更新状态动作空间中各项的Q值,适用于状态动作空间较小的情况。**考虑到实际系统模型的复杂性,这些空间通常是非常大的。原因是大量状态很少被访问,对应的Q值很少更新,导致Q函数的收敛时间较长。**DQN通过将深度神经网络(DNNs)与q学习相结合,解决了Q-learning算法的不足。DQN的核心思想是利用 θ 参数化的DNN来求得近似的Q值 Q(s,a) 代替 Q 表,即 Q(s,a∣θ)≈Q∗(s,a) 。
但是使用 DNN 的 RL 算法的稳定性不能得到保证。为了解决这个问题,采用了两种机制。第一个是体验重放(experience replay)。在每个时间步 i 中,agent的交互经验元组 (si,ai,ri,si+1) 存储在经验重放缓冲区,即经验池 Bm。然后,从经验池中随机选取少量样本,即小批量,对深度神经网络的参数进行训练,而不是直接使用连续样本进行训练。第二种稳定方法是使用一个目标网络,它最初包含了设定策略的网络的权值,但在固定的时间步长内保持冻结状态。目标Q网络更新缓慢,但主Q网络更新频繁。这样大大降低了目标与估计Q值之间的相关性,使得算法更加稳定。
在每次迭代中,通过最小化损失函数 L(θ),将深度 Q 函数训练到目标值。损失函数可以写成:
L(θ)=E[(y−Q(s,a∣θ))2]
其中目标值 y 表示为 y=r+γmaxa′Q(s′,a′∣θi−) 。在 Q-learning 中,权值 θi−=θi−1 ,而在深度 q 学习 θi−=θ1−X ,即目标网络权值每 X 个时间步更新一次。
3.1.4 DDPG
**DQN算法虽然可以解决高维状态空间的问题,但仍然不能处理连续的动作空间。DDPG算法是一种基于DNN的无模型的 off-policy actor - critic算法,可以学习连续动作空间中的策略。**该算法由策略函数和 q 值函数组成。策略函数扮演一个参与者来生成动作。q 值函数作为一个批评家,评价行为人的表现,并指导行为人的后续行动。
如图1所示,DDPG使用两个不同的 DNNs 来逼近actor网络 μ(s∣θμ) (即policy function)和critic 网络 Q(s,a∣θQ) (即Q-value funtion)。另外,行动者网络和批评网络都包含一个与它们结构相同的目标网络:使用参数 θμ′ 的行动者目标网络 μ′ ,使用参数 θQ′ 的批评目标网络 Q′。与 DQN 相似,批评家网络 Q(s,a∣θQ) 可以更新如下:
L(θQ)=Eμ′[(yi−Q(si,ai∣θQ))2]
其中,
yi=ri+γQ(si+1,μ(si+1)∣θQ)
正如Silver等人所证明的,策略梯度可以用链式法则更新,
∇θμJ≈Eμ′[∇θμQ(s,a∣θQ)∣∣∣s=si,a=μ(si∣θμ)]=Eμ′[∇aQ(s,a∣θQ)∣∣∣s=si,a=μ(si∣θμ)∇θμμ(s∣θμ)∣∣∣∣s=si].
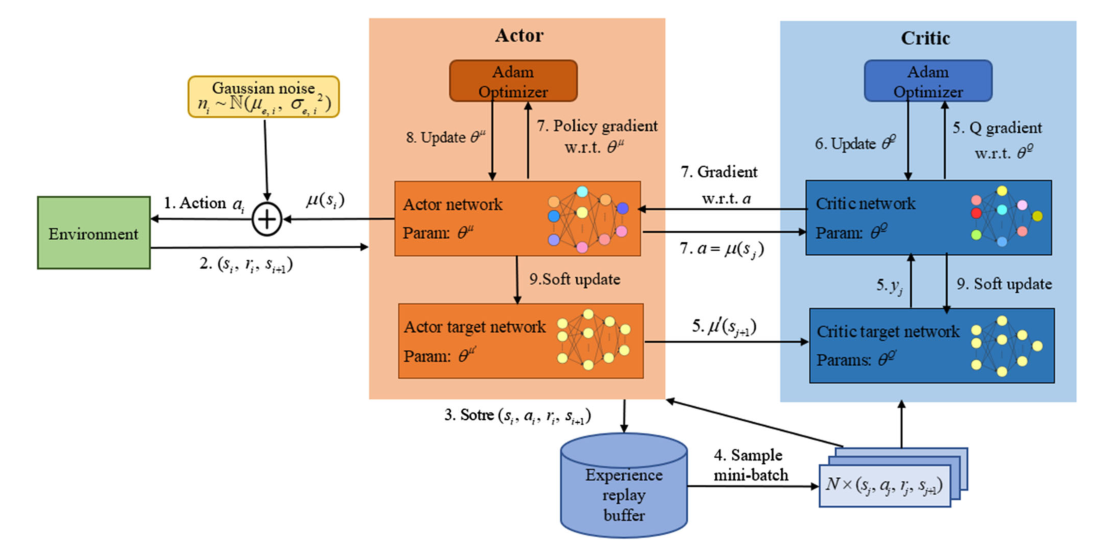
DDPG 算法的整个训练过程可以总结如下:首先,演员网络 μ 在上一个训练步骤之后输出 μ(si)。**为了提供充分的状态空间探索,我们需要在探索和开发之间取得平衡。**实际上,我们可以将 DDPG 的探索与学习过程分开来看待,因为 DDPG 是一种 off-policy 算法。因此,我们通过添加行为噪声 ni 来构造动作空间,以获得动作 ai=μ(si)+ni ,其中 ni 服从高斯分布 ni∼N(μe,σe,i2) , μe 为平均值, σe,i 是标准差。在环境中表演 at 后,agent 可以观察到下一个状态 si+1 和即时奖励 rt。然后将元组 (si,ai,ri,si+1) 存储在体验回放缓冲区中。之后,算法随机选择N个元组 (sj,aj,rj,sj+1) 在缓冲区中组成一个小批量,并将其输入演员网络和评论家网络。使用小批处理,演员目标网络 μ′ 将行为 μ′(sj+1) 输出到评论目标网络 Q′。利用 minibatch 和 μ′(sj+1) ,批评家网络可以根据 yi=ri+γQ(si+1,μ(si+1)∣θQ) 计出目标值 yj。
**为了使损失函数最小化,批评家网络Q将由给定的优化器(如Adam optimizer)进行更新。**然后,演员网络 μ 将小批量动作 a=μ(sj) 发送给评论网络,以实现动作a的梯度 ∇aQ(s,a∣θQ)∣∣∣s=sj,a=μ(sj) 。参数 ∇θμμ(s∣θμ)∣s=sj 可以由它自己的优化器导出。使用这两个梯度,参与者网络可以用以下近似更新:
∇θuJ≈N1j∑[∇aQ(s,a∣θQ)∣∣∣s=sj,a=μ(sj∣θμ)∇θμμ(s∣θμ)∣∣∣∣s=sj].
最后,DDPG agent使用小常数 τ 柔化更新批评家目标网络和行动者目标网络:
θQ′←θQ+(1−τ)θQ′θμ′←θμ+(1−τ)θμ′