强化学习系列(一):强化学习简介
参考链接:
https://blog.csdn.net/LagrangeSK/article/details/80943045
https://blog.csdn.net/qq_37402392/article/details/121348504?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_37402392/article/details/121490296?spm=1001.2014.3001.5501
术语表
agent——整体
environment——环境
action——动作
state——状态
reward——奖惩
label——标签
policy——策略
value function——价值函数
model——模型
Exploration——探索
Exploitation——利用
1、强化学习是什么?
首先,我们思考一下学习本身,当一个婴儿在玩耍时可能会挥舞双手,左看右看,没有人来指导他的行为,但是他和外界直接通过了感官进行连接。感知给他传递了外界的各种信息,包括知识等。学习的过程贯穿着我们人类的一生,当我们开车或者说话时,都观察了环境,并执行一系列动作来影响环境。强化学习描述的是一个与环境交互的学习过程。
那么强化学习是如何描述这一学习过程的呢?以人开车为例,将人和车作为一个整体(agent),外界红绿灯、车道线等信息构成了环境(environment),然后人通过控制车辆向左、向右转弯或者直行的动作(action),影响了这个环境的状态(state),比如说前方有车,向右转弯后车道前没有车辆,这就说明车辆的动作影响了环境的状态。
但是,仅仅有了agent、environment、state和action还不够,需要有一个奖惩来指导agent的行动,这就是reward,比如车辆闯红灯会收到罚单。那么说到这里,大家一定很好奇:reward是如何指导强化学习的呢?首先我们要从强化学习的特性说起。
2、强化学习特性
强化学习作为机器学习的一种,免不了要被拿来和监督学习以及无监督学习比较。
首先,监督学习的特点是学习的数据都有标签(labels),即我们在学习之前就以及告知了模型什么样的state下采用什么样的action是正确的,简单说就是有个专门的老师(或者监督者)告诉算法,什么是对什么是错,通常用于回归,分类问题。无监督学习则恰恰相反,其所用于学习是数据没有标签(label)的,而是通过学习无标签的数据来探索数据的特性,通常用于聚类。
上文说到,强化学习是与环境实时交互并且会通过动作影响环境的,我们所采用的数据是没有一个正确的标签(label)明确告诉我们哪种动作(action)是好哪种是坏。但是我们提到了用一种特殊的奖惩机制来引导动作(action),那就是奖惩(reward)。 奖惩(reward)并不像标签(label)一样,是在学习前就已经存在与数据中,而是在当前时刻 t 的状态 下,执行了相应的动作 , 才会在下一时刻(t+1时刻)获得一个对 t 时刻的奖惩(reward) ,存在延迟。奖惩(reward)本来就是一种延迟奖励的机制,另外,有些动作(action)通过对环境状态(state)的影响,可以影响到好多步之后的奖惩(reward), 因此强化学习的目标为最大化奖惩(reward)之和,而不是单步奖惩(reward)。
说了那么多,现在可以总结一下强化学习的特性啦!强化学习有如下特点:
- 没有监督者,只有一系列的奖惩(reward)
- 反馈不是及时的,而是延时的
- 算法接受的数据是有时间顺序的
- 整体(agent)的动作可以对环境产生持续影响
对第三点而言,需要额外解释一下,在监督学习中,通常假设数据是通过独立同分布采样的,即假设所有的样本数据都是通过在同一个分布下(如高斯分布)独立采样获得,而这一点对于强化学习来说,明显是不大可能,**因为强化学习是一种与环境交互的学习问题,这意味着状态(state)和动作(action)的时序性是很重要的,他所获得的一系列状态(state)很大程度上是有联系的,并不是独立存在的。**比如用强化学习下棋的例子中,当前落子位置会影响后面的落子。
3、强化学习问题
强化学习定义的是一类问题,即强化学习问题,用于解决该类问题的方法我们称之为强化学习方法。第一节中,我们说到强化学习的几个组成部分:奖惩(reward)、整体(agent)、环境(environment)、状态(state)、动作(action)。第二节中,我们明确了强化学习的目的为选择动作(action)用以最大化所有未来的reward(reward之和),下面我们将分别介绍其他几个部分是如何影响强化学习工作的。
3.1 整体(agent)与环境(environment)
整体(agent)与环境(environment)的交互过程如下图所示,其中大脑表示整体(agent),地球表示环境(environment)。
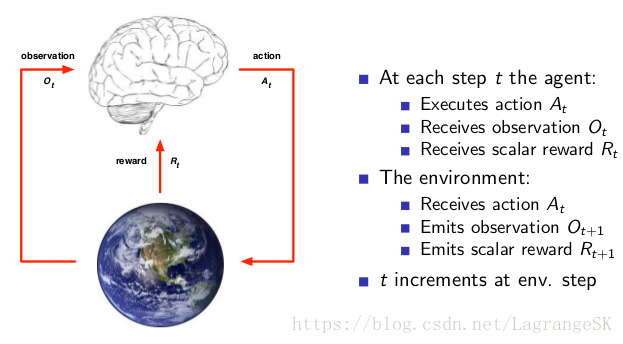
每 t 时刻, 整体(agent)完成以下过程:
- 执行动作(action) ,影响环境
- 观测到观测量(observation)
- 收到环境反馈的奖惩(reward)
环境(environment)完成以下工作:
- 接收动作(action)
- 更新观测量(observation)
- 产生奖惩(reward)
需要注意整体(agent)与环境(environment)之间的界限问题,并不是严格的物理界限,比如一个机器人和外界这样的关系,当我们考虑机器人如何决策时(如决定往哪前进),机器人的决策部分作为一个整体(agent),而他的控制系统则可以看做是环境(environment)的一部分。如何界定整体(agent)和环境(environment):
整体-环境边界代表代理绝对控制的限制,而不是其知识的限制。
The agent-environment boundary represents the limit of the agent’s absolute control, not of its knowledge.
3.2 状态(state)
通过观察上图,发现状态(state)还没出现,接下来我们讨论一下上图中的观测量(observation)是如何转变为我们常用状态(state)的。
首先,假设我们执行上述强化学习过程一段时间并将其存储下来,那么这些信息就构成了历史数据(history),即由一系列的观测量(observation)、reward、action组成。
那么这些历史数据可以用来干啥呢?我们有了历史数据,就可以用于让agent选择action,让environment选择observation和reward。而根据状态(state)的定义,状态(state)是用来决定下一步做什么的信息量,那么既然history 有这样的作用,可以将状态(state)看做是history 的函数:
状态(state)可以分为环境状态(environment state)、智能体状态(agent state)和信息状态(information state),前两者顾名思义,environment state为环境的内部状态,即environment采用哪些信息来选择下一步的observation和reward(通常对agent不可见,如果可见常常包括冗余信息),agent state 为agent内部状态,即哪些信息用于选择下一步的动作,这是强化学习算法直接采用的信息,可以表示为历史的任意函数 。
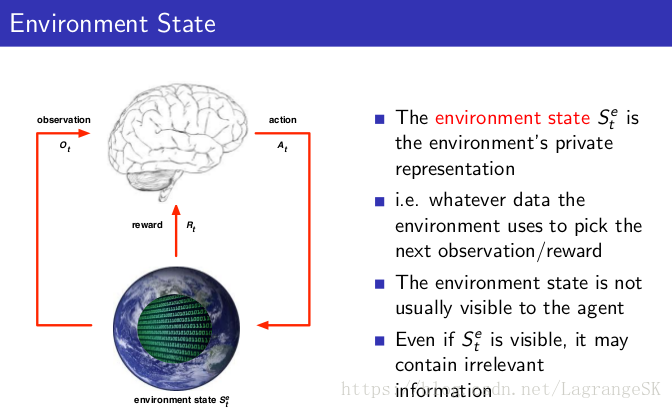
- 环境状态 是环境的私有表示。
- 环境用来挑选下一个观察/奖励的任何数据。
- 环境状态通常对整体不可见。
- 即使 是可见的,它也可能包含不相关的信息。

- 智能体状态 是智能体的内部表示。
- 智能体用来挑选下一个观察/奖励的任何数据。
- 是被强化学习算法使用的信息。
- 它可以作为历史信息history的函数:

而information state包括了历史数据中所有有用的信息,当state满足马尔科夫条件(见下图),则下一时刻的状态完全由当前时刻决定,可以将其他历史信息扔掉啦!
状态 当且仅当满足以下条件是马尔科夫性的:
- 只考虑到现在,未来是独立于过去的。
- 一旦状态是已知的,历史信息就会被扔掉
- state是一个具有充分未来信息的统计量
- 环境状态 是马尔科夫性的
- 历史 是马尔科夫性的
定义了这三个状态(state),我们可以将环境分为可完全观测环境(Fully Observation Environment)和部分可观测环境(Partially Observation Environment)。
当环境完全可观测时,有如下特点:
- Agent state = environment state = information state
- 这是一个马尔科夫过程(详情见强化学习系列(三):马尔科夫过程)
部分可观测环境,即环境的一部分信息对agent不可见,如玩扑克不知道对方的牌。此时:
- Agent state != environment state
- 是部分可观测马尔科夫过程(POMDP)
- agent 需要根据观测量observation构建agent state SatSta
4、agent组成要素
上一节阐述了agent和environment的交互过程,环境主要在于提供reward和observation,那么构建一个agent需要哪些要素呢?
一个强化学习的智能体(agent)主要包括以下一个或多个要素:
- 策略Policy:agent’s behaviour function
- 价值函数Value function:how good is each state and/ or action
- 模型(Model):agent’s representation of the environment
4.1 策略(policy)
策略,简言之就是agent的行为准则,对应着action和state之间的关系。
- 通常分为确定性策略(deterministic policy): ,即一个action为state的函数。
- 随机策略(stochastic policy): ,对应action相对state的条件概率。
4.2 价值函数(Value function)
强化学习的目标为最大化reward之和,但不是每一个学习过程都有终止状态,那么reward之和不能简单计算,所以需要用一个价值函数来估计未来的reward。具体表达说到强化学习的具体表示时再讨论。
4.3 模型(Model)

- 一个预测环境environment将如何做的模型
- P预测下一个state
- R预测下一个(即时)奖惩reward
根据包不包含Policy 和value function可以将强化学习方法进行分类:基于价值、基于概率以及Actor-Critic(actor 会基于概率做出动作, 而 critic 会对做出的动作给出动作的价值, 这样就在原有的 policy gradients 上加速了学习过程。)

根据是否建立了模型,可以将强化学习方法分类:Model-free 中(agent等待真实世界的反馈, 再根据反馈采取下一步行动)和 model-based(agent能通过想象来预判断接下来将要发生的所有情况。然后选择这些想象情况中最好的那种。)

5.、探索(Exploration)和利用(Exploitation)
在讨论Exploration and Exploitation之前。思考一件事情,假如你要去吃饭了,是选择你已经知道的餐馆中最符合你胃口的(Exploitation),这样保证你会满意。还是尝试一个你从未去过的餐馆(Exploration),可能你会有更好的用餐体验?当然也可能会很糟糕。
强化学习作为一种探索试错学习,agent需要发现一个好的策略,为了发现这个好的策略,他需要平衡这两者间的关系:
Exploration:不断探索新的环境信息,换言之,就是要不断扩大state的地图,不断搜索以前没遇到的state,并挑战不同的action
Exploitation: 对已经探索到的环境信息选择可以获得最大reward的action。
需要平衡两者间的关系,强化学习系列(二)中我们针对Multiarmed bandit problem(多臂老虎机问题)探讨一些用于平衡两者关系的方法。
David Silver 课程
Reinforcement Learning: an introduction
categories:
- 人工智能