Python中Pandas的DataFrame对象的行以及列的增删改查
参考链接:
https://www.cnblogs.com/datasnail/p/9675410.html
https://blog.csdn.net/qq_40981268/article/details/86498672
https://www.cnblogs.com/guxh/p/9420610.html
https://www.cnblogs.com/zmc940317/p/13608237.html
https://www.cnblogs.com/datasnail/p/9757081.html
https://github.com/dataSnail/blogCode/tree/master/python_curd
pandas DaFrame的创建方法
在pandas里,DataFrame是最经常用的数据结构,这里总结生成和添加数据的方法:
①把其他格式的数据整理到DataFrame中;
②在已有的DataFrame中插入N列或者N行。
1. 字典类型读取到DataFrame(dict to DataFrame)
假如我们在做实验的时候得到的数据是dict类型,为了方便之后的数据统计和计算,我们想把它转换为DataFrame,存在很多写法,这里简单介绍常用的几种:
**方法一:**直接使用pd.DataFrame(data=test_dict)即可,括号中的data=写不写都可以,具体如下:
1 | |
那么,我们就得到了一个DataFrame,如下:
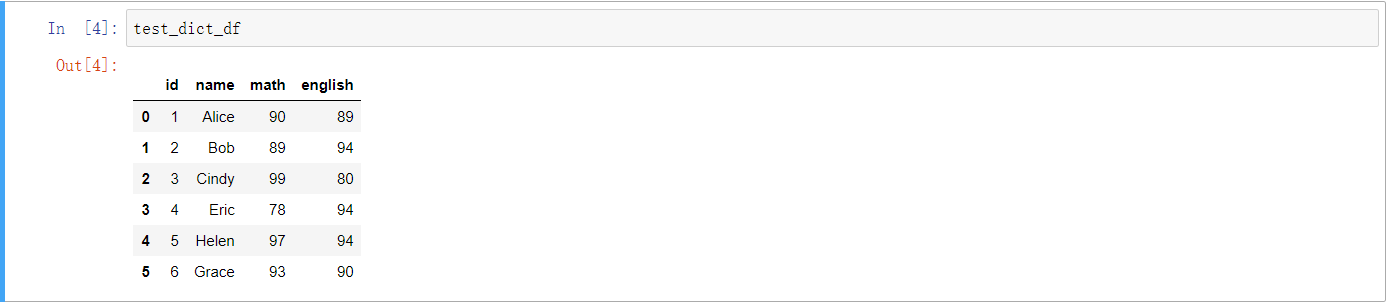
应该就是这个样子了。
**方法二:**使用from_dict方法:
1 | |
结果是一样的,不再重复贴图。
**其他方法:**如果你的dict变量很小,例如{'id':1,'name':'Alice'},你想直接写到括号里:
1 | |
这样是不行的,会报错ValueError: If using all scalar values, you must pass an index,是因为如果你提供的是一个标量,必须还得提供一个索引Index,所以你可以这么写:
1 | |
后面的可以写多个pd.Index(range(3),就会生成三行一样的,是因为前面的dict型变量只有一组值,如果有多个,后面的Index必须跟前面的数据组数一致,否则会报错:
1 | |
关于选择列,有些时候我们只需要选择dict中部分的键当做DataFrame的列,那么我们可以使用columns参数,例如我们只选择’id’,'name’列:
1 | |
这里就不在多写了,后续变更颜色添加内容。
2. csv文件构建DataFrame(csv to DataFrame)
我们实验的时候数据一般比较大,而csv文件是文本格式的数据,占用更少的存储,所以一般数据来源是csv文件,从csv文件中如何构建DataFrame呢? txt文件一般也能用这种方法。
方法一:最常用的应该就是pd.read_csv('filename.csv')了,用 sep指定数据的分割方式,默认的是','
1 | |
如果csv中没有表头,就要加入head参数
pandas DataFrame的查询方法
在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧。
首先,还是列出一个我们用的DataFrame,注意index一列,如下:
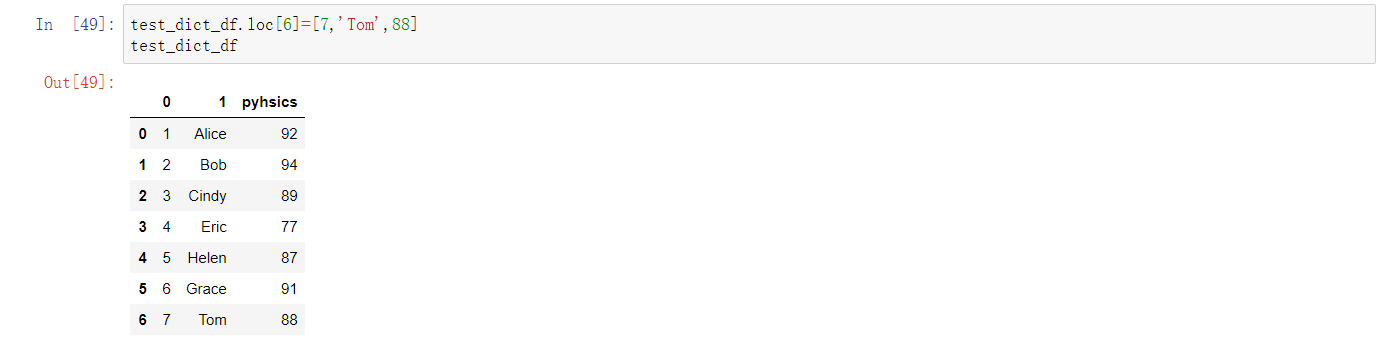
接下来,介绍下各个函数的用法:
1、loc函数
愿意看官方文档的,请戳这里,这里一般最权威。
loc函数是基于“标签”选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例:
1.1 单个label
接受一个“标签”(label)参数,返回一个Series,例如下面这个例子收一个标签,返回通过这个标签定位的行的值,注意这里是通过标签定位,而不是通过中括号中的数字定位第几行,之后我们通过对比iloc函数时还会细说。
1 | |
1.2 一个label的array
如果键入一个标签的array,那么就返回一个对应的DataFrame:
1 | |
结果如下:
1.3 加入一个切片array
1 | |
结果如下:
1.4 行标签,列标签
通过在中括号中加入行标签和列标签来定位一个cell(单元格),相当于坐标的定位:
1 | |
1.5 行标签或者列标签是切片array
1 | |
1.6 还可以接受条件,进行选择
例如我们选择英语成绩超过90的所有行:
1 | |

当然,也可以再条件选择后,再加入列选择,列选择的时候可以单列,也可以是切片数组,通过上面的介绍这里就可以灵活处理:
1 | |
1.7 接受一个boolean的array
可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值
1 | |
loc还有很多用法,这里先介绍到这里吧,当然如果你的DataFrame是复合的行或者复合列,写法也是不同的,具体就可以查阅官方文档了!
2、iloc函数
官方文档戳这里。
iloc函数与loc函数不同的是,它接受的是一个数字,代表着要选择数据的位置:
1 | |
这代表我们选择的是第6行,而不是index为6的那一行。当然,也可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值:
1 | |
这里iloc也可以接受切片array:
1 | |
3、ix函数(0.20.0版本后已经弃用)
ix就是一种混合索引,字符串的标签和证书的数据索引都可以作为合法输入,其实相当于loc和iloc的一个混合方法:
1 | |
上述两种方法都能得到值,这里我们就不追究这个函数具体是怎样的检索顺序或者工作原理了。因为官方给出的是从pandas0.20.0之后,ix函数已经被弃用。其实在使用的时候,ix函数虽然方便,但是的确有时候会显得比较混乱,所以我们之后也尽量少用这个函数吧,还是按照官方大佬的指导。
4、at函数
at是用来选择单个值的,此时用法类似于loc:
1 | |
以上两种方法都能选择到,label为1,列为’english’的那个值,但是据说at速度要快,这点我没有考证过。
5、iat函数
iat函数相对于at函数,就相当于iloc相对于loc函数。iat也只能选择一个值。只不过是用索引位置来选择,注意:行列都是索引位置来选择,从0开始数。
1 | |
6、概括一下
最后我们概括一下:
1、 loc和iloc函数都是用来选择某行的,iloc与loc的不同是:iloc是按照行索引所在的位置来选取数据,参数只能是整数。而loc是按照索引名称来选取数据,参数类型依索引类型而定;
2、 at和iat函数是只能选择某个位置的值,iat是按照行索引和列索引的位置来选取数据的。而at是按照行索引和列索引来选取数据;
3、 loc和iloc函数的功能包含at和iat函数的功能。
pandas DataFrame行或列的删除方法
平时在用DataFrame时候,删除操作用的不太多,基本是从源DataFrame中筛选数据,组成一个新的DataFrame再继续操作。
1. 删除DataFrame某一列
2.1,del
1 | |
2.2,drop
我们使用drop()函数,此函数有一个列表形参labels,写的时候可以加上labels=[xxx],也可以不加,列表内罗列要删除行或者列的名称,默认是行名称,如果要删除列,则要增加参数axis=1,操作如下:
1 | |
这里注意输出的结果是执行此方法的结果,而不是输出test_dict_df的结果,是因为方法默认的并不是在本身执行操作,这时候输出test_dict_df输出的仍然是没有进行删除操作的原DataFrame,如果你想在原DataFrame上进行操作,需要加上inplace=True,等价于在操作完再赋值给本身。
使用列数删除,传入参数是int,列表,者切片:
1 | |
2.3,通过各种筛选方法实现删除列
请注意一定要传入索引。
2.4,删除/选取某列含有特殊数值的行
1 | |
2. 删除DataFrame某一行
2.1,drop
通过行名称删除:
1 | |
删除某一行,在上面删除列操作的时候也稍有提及,如果不加axis=1,则默认按照行号进行删除,例如要删除第0行和第4行:
1 | |
同理,你要在源DataFrame上进行操作就得加上inplace参数,否则不会在test_dict_df上改动。
当然,如果你的DataFrame有很多级,你可以加上level参数,这里就不多赘述了。
2.2,通过各种筛选方法实现删除行
详见pandas“选择行单元格,选择行列“的笔记
举例,通过筛选可以实现很多功能,例如要对某行数据去重,可以获取去重后的index列表后,使用loc方法:
1 | |
2.3,删除/选取某行含有特殊数值的列
1 | |
3.删除含有空值的行或列
实现思路:利用pandas.DateFrame.fillna对空值赋予特定值,再利用上文介绍的方法找到这些含有特定值的行或列去除即可。
1 | |
4添加列
一般涉及到增加列项时,经常会对现有的数据进行遍历运算,获得新增列项的值,所以这里结合对DataFrame的遍历讨论增加列。
例如,想增加一列’E’,值等于’A’和’C’列对应值之和。
4.1,遍历DataFrame获取序列的方法
1 | |
4.2,[ ],loc
通过df[]或者df.loc添加序列
1 | |
4.3,Insert
可以指定插入位置,和插入列名称
1 | |
此时,就得到了添加好的DataFrame,需要注意的是DataFrame默认不允许添加重复的列,但是在insert函数中有参数allow_duplicates=True,设置为True后,就可以添加重复的列了,列名也是重复的。
4.4,concat
1 | |
4.5,iloc和loc遍历过程中给列赋值
效率比较低
df[‘E’]是DataFrame的一个Series,是引用,对其修改也能改变DataFrame,但运行时报了Warning
1 | |
不用Series不会报Warning:
1 | |
用loc无需先给E列赋空值:
1 | |
4.6,逐列增加
简单的逐列添加内容,可以:
1 | |
但需要注意:len(df)生成的是int,如果生成的int,df已经存在了,会覆盖该列数据,而不会新增
4.7,其他方法
增加3列,EFG,value默认为np.NaN
1 | |
5 添加行
5.1,loc,at,set_value
想增加一行,行名称为‘5’,内容为[16, 17, 18, 19]
1 | |
5.2,append
添加有name的Series:
1 | |
添加没有name的Series,必须ignore_index:
1 | |
可以 append字典列表,同样需要必须ignore_index:
1 | |
5.3,逐行增加
简单的逐行添加内容,可以:
1 | |
但需要注意:len(df)生成的是int,如果生成的int,df已经存在了,会覆盖该行数据,而不会新增
5.4,插入行
增加行没找到类似insert这种可以插入的方法,暂时替代方法可以先reindex,再赋值:
1 | |
pandas DataFrame的修改方法
对于DataFrame的修改操作其实有很多,不单单是某个部分的值的修改,还有一些索引的修改、列名的修改,类型修改等等。我们仅选取部分进行介绍。
一、值的修改
DataFrame的修改方法,其实前面介绍loc方法的时候介绍了一些。
1、 loc方法修改
loc方法实际上是定位某个位置的数据的,但是定位完以后就可以对此位置的数据进行修改,使用此方法可以对DataFrame进行的修改如下:
- 对某行、某N行进行修改;
- 对某列、某N列进行修改;
- 对横坐标为某行或某N行,纵坐标为某列或者某N列的数据进行修改;
可以看出基本用loc方法我们对DataFrame可以进行任意修改了。
1.1 对某行、某N行进行修改
1 | |
可以看出具体的方法就是用loc方法,对某行或者某N行进行定位,然后赋予合适的格式的值就可以了。
1.2 对某列、某N列进行修改
学会了使用loc方法对行的修改,那触类旁通,对列的修改也很简单了。对列修改也就是修改此列的所有行。
1 | |
1.3 对某个区域的值进行修改
1 | |
1.4 总结
可以看到loc方法就是,只要你能选到某个或者某个区域的值,然后就可以对此部分的值进行修改。但是要注意赋值部分的组织方式。
2、 iloc、at、iat方法修改
类比于上面的方式,其实只要能选择,都是可以修改的。选择方法可以看pandas DataFrame的查询(选择)篇。
二、列名的修改
1、直接全部更改
这种方法是对DataFrame的列名进行重新赋值,比较暴力直接。
1 | |
2、使用rename方法
这种方法是比较推荐的,通过rename方法,注意参数inplace=True的时候,才能真正的在原来的DataFrame上进行修改。
1 | |
三、索引的修改
1、修改索引名称
上面的rename方法,如果不写columns=xx就默认修改索引了 。
1 | |
2、重置索引
通过reset_index()方法我们可以重置索引,drop参数为True时,直接丢弃原来的索引,否则原来的索引新生成一列名为’index’的列:
1 | |
2、设置其他列为索引
当然我们也可以用其他列为索引,通过set_index()方法:
1 | |
四、总结
可以看到,所谓的修改首先要能选择修改的位置,即定位,然后对确定好的位置进行重新赋值,所以我们学会了如何选择数据,也就基本能修改此处的数据。
dataframe的拼接与合并
1、merge
1 | |
left︰ 对象
right︰ 另一个对象
on︰ 要加入的列 (名称)。必须在左、 右综合对象中找到。如果不能通过 left_index 和 right_index 是假,将推断 DataFrames 中的列的交叉点为连接键
left_on︰ 从左边的综合使用作为键列。可以是列名或数组的长度等于长度综合
right_on︰ 从正确的综合,以用作键列。可以是列名或数组的长度等于长度综合
left_index︰ 如果为 True,则使用索引 (行标签) 从左综合作为其联接键。在与多重 (层次) 的综合,级别数必须匹配联接键从右综合的数目
right_index︰ 相同用法作为正确综合 left_index
how︰ 之一 ‘左’,‘右’,‘外在’、 ‘内部’。默认为内部。每个方法的更详细说明请参阅︰
sort︰ 综合通过联接键按字典顺序对结果进行排序。默认值为 True,设置为 False将提高性能极大地在许多情况下
suffixes︰ 字符串后缀并不适用于重叠列的元组。默认值为 (‘_x’,‘_y’)。
copy︰ 即使重新索引是不必要总是从传递的综合对象,复制的数据 (默认值True)。在许多情况下不能避免,但可能会提高性能 / 内存使用情况。可以避免复制上述案件有些病理但尽管如此提供此选项。
indicator︰ 将列添加到输出综合呼吁 _merge 与信息源的每一行。_merge 是绝对类型,并对观测其合并键只出现在 ‘左’ 的综合,观测其合并键只会出现在 ‘正确’ 的综合,和两个如果观察合并关键发现在两个 right_only left_only 的值。
1 | |
2、append
1 | |
3、join
1 | |
4、concat
1 | |
objs︰ 一个序列或系列、 综合或面板对象的映射。如果字典中传递,将作为键参数,使用排序的键,除非它传递,在这种情况下的值将会选择 (见下文)。任何没有任何反对将默默地被丢弃,除非他们都没有在这种情况下将引发 ValueError。
axis: {0,1,…},默认值为 0。要连接沿轴。
join: {‘内部’、 ‘外’},默认 ‘外’。如何处理其他 axis(es) 上的索引。联盟内、 外的交叉口。
ignore_index︰ 布尔值、 默认 False。如果为 True,则不要串联轴上使用的索引值。由此产生的轴将标记 0,…,n-1。这是有用的如果你串联串联轴没有有意义的索引信息的对象。请注意在联接中仍然受到尊重的其他轴上的索引值。
join_axes︰ 索引对象的列表。具体的指标,用于其他 n-1 轴而不是执行内部/外部设置逻辑。
keys︰ 序列,默认为无。构建分层索引使用通过的键作为最外面的级别。如果多个级别获得通过,应包含元组。
levels︰ 列表的序列,默认为无。具体水平 (唯一值) 用于构建多重。否则,他们将推断钥匙。
names︰ 列表中,默认为无。由此产生的分层索引中的级的名称。
verify_integrity︰ 布尔值、 默认 False。检查是否新的串联的轴包含重复项。这可以是相对于实际数据串联非常昂贵。
副本︰ 布尔值、 默认 True。如果为 False,请不要,不必要地复制数据。