参考链接:
https://www.cnblogs.com/lemonbit/p/6810972.html
https://blog.csdn.net/u011675334/article/details/105328857
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。对DataFrame的列应用各种各样的函数。应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等。计算透视表或交叉表。执行分位数分析以及其他分组分析。
groupby分组函数:
返回值:返回重构格式的DataFrame,特别注意,groupby里面的字段内的数据重构后都会变成索引
groupby()一般和sum()、mean()一起使用。
1 2 import pandas as pdimport numpy as np
1 df = pd.DataFrame({'A' : ['a' , 'b' , 'a' , 'c' , 'a' , 'c' , 'b' , 'c' ], 'B' : [2 , 8 , 1 , 4 , 3 , 2 , 5 , 9 ],'C' : [102 , 98 , 107 , 104 , 115 , 87 , 92 , 123 ]})
1 df.groupby(['A' ,'B' ]).mean()
分组后,可以选取单列数据,或者多个列组成的列表(list)进行运算
1 2 3 4 5 6 df = pd.DataFrame([[1 , 1 , 2 ], [1 , 2 , 3 ], [2 , 3 , 4 ]], columns=["A" , "B" , "C" ])"A" )'B' ].mean() 'B' , 'C' ]].mean()
1 g.agg({'B' :'mean' , 'C' :'sum' })
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
1 df = pd.DataFrame({"Name" :["Alice" , "Bob" , "Mallory" , "Mallory" , "Bob" , "Mallory" ],"City" :["Seattle" , "Seattle" , "Portland" , "Seattle" , "Seattle" , "Portland" ],"Val" :[4 ,3 ,3 ,np.nan,np.nan,4 ]})
count()
1 df.groupby(["Name" , "City" ], as_index=False )['Val' ].count()
size()
1 df.groupby(["Name" , "City" ])['Val' ].size().reset_index(name='Size' )
针对某列使用agg()时进行不同的统计运算
1 2 df = pd.DataFrame({'A' : list ('XYZXYZXYZX' ), 'B' : [1 , 2 , 1 , 3 , 1 , 2 , 3 , 3 , 1 , 2 ],'C' : [12 , 14 , 11 , 12 , 13 , 14 , 16 , 12 , 10 , 19 ]})'A' )['B' ].agg({'mean' :np.mean, 'standard deviation' : np.std})
针对不同的列应用多种不同的统计方法
1 df.groupby('A' ).agg({'B' :[np.mean, 'sum' ], 'C' :['count' ,np.std]})
apply函数针对groupby后的DataFrame执行参数中所指定的函数。
1 2 3 4 5 df = pd.DataFrame({'A' : list ('XYZXYZXYZX' ), 'B' : [1 , 2 , 1 , 3 , 1 , 2 , 3 , 3 , 1 , 2 ],'C' : [12 , 14 , 11 , 12 , 13 , 14 , 16 , 12 , 10 , 19 ]})'A' ).apply(np.mean)
apply()方法可以应用lambda函数,举例如下:
1 2 3 df.groupby('A' ).apply(lambda x: x['C' ]-x['B' ])'A' ).apply(lambda x: (x['C' ]-x['B' ]).mean())
前面进行聚合运算的时候,得到的结果是一个以分组名为 index 的结果对象。如果我们想使用原数组的 index 的话,就需要进行 merge 转换。
transform(func, *args, **kwargs) 方法简化了这个过程,它会把 func 参数应用到所有分组,然后把结果放置到原数组的 index 上(如果结果是一个标量,就进行广播):
1 2 3 4 5 df = pd.DataFrame({'group1' :['A' , 'A' , 'A' , 'A' ,'B' , 'B' , 'B' , 'B' ],'group2' :['C' , 'C' , 'C' , 'D' ,'E' , 'E' , 'F' , 'F' ],'B' :['one' , np.NaN, np.NaN, np.NaN,np.NaN, 'two' , np.NaN, np.NaN],'C' : [np.NaN, 1 , np.NaN, np.NaN,np.NaN, np.NaN, np.NaN, 4 ]}) 'group1' , 'group2' ])['B' ].transform('count' )'count_B' ]=df.groupby(['group1' , 'group2' ])['B' ].transform('count' )
1 2 np.random.seed(0 )'Age' : np.random.randint(20 , 70 , 100 ),'Sex' : np.random.choice(['Male' , 'Female' ], 100 ),'number_of_foo' : np.random.randint(1 , 20 , 100 )})
这里将“Age”列分成三类,有两种方法可以实现:
(a)bins=4(指定分组个数)
(b)bins=[19, 40, 65, np.inf](指定界限范围)
1 2 pd.cut(df['Age' ], bins=4 )'Age' ], bins=[19 ,40 ,65 ,np.inf])
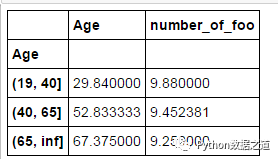
分组结果范围结果如下:
1 2 age_groups = pd.cut(df['Age' ], bins=[19 ,40 ,65 ,np.inf])
运行结果如下:
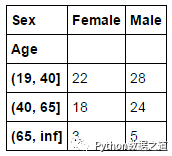
按‘Age’分组范围和性别(sex)进行制作交叉表
1 pd.crosstab(age_groups, df['Sex' ])
运行结果如下:
通过reset_index()函数将groupby()的分组结果转换成DataFrame对象。
代码举例:
1 2 3 4 5 6 7 total = df.groupby(['A' ])['B' ].count()'total' :total})'A' ])['B' ].sum ()'bad' :bad})True ,right_index=True , how='left' )True )
完整报错如下:
1 AttributeError: Cannot access callable attribute 'sort_values' of 'DataFrameGroupBy' objects, try using the 'apply' method
报错代码如下:
1 2 3 4 5 import pandas as pd'test.csv' ,header = 0 )'date' , group_keys=False ).sort_values('Value' , ascending=False ).groupby('date' ).head(10 ).reset_index()print (df)
报错原因:
groupby 之后变成了 DataFrameGroupBy,不能直接调用 sort_values() 函数,需使用 apply() 函数 ,代码更改为如下:
1 2 3 4 5 6 import pandas as pd'test.csv' ,header = 0 )'date' , group_keys=False ).apply(lambda x: x.sort_values('virus_connectivity' , ascending=False )).groupby('date' ).head(10 ).reset_index()print (df)