数据挖掘原理-概论(1)
1.数据挖掘的概念
数据挖掘(Data Mining,DM)又称数据库中的知识发现(Knowledge Discover in Database,KDD),是涉及机器学习、人工智能、数据库理论以及统计学等学科的交叉研究领域。
数据挖掘就是从数据库的大量数据中挖掘出有用的信息,即从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,发现隐含的、规律性的、人们事先未知的,但又是潜在有用的并且最终可理解的信息和知识的非平凡过程。
2.数据挖掘的历史及发展数据挖掘
数据挖掘(Data Mining,DM)是知识发现(KDD)最核心的部分。(数据挖掘与知识发现的关系)
数据挖掘数学理论基础的发展,与统计学的发展密不可分。
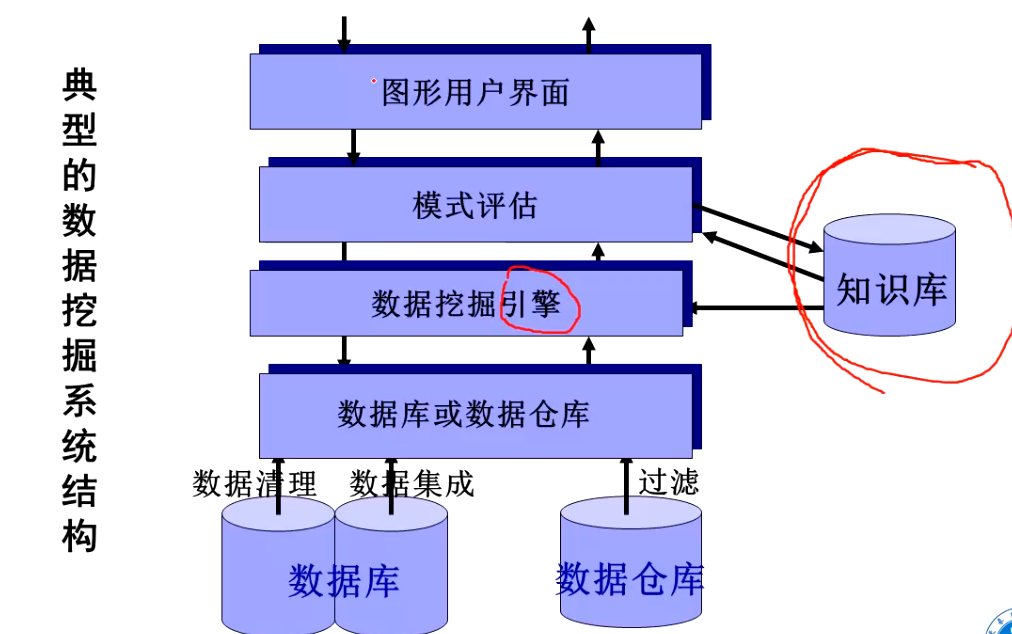
数据挖掘中还存在许多问题有待进一步研究,包括下列几个研究方向:
①算法效率和可伸缩性
②处理不同类型的数据和数据源
③数据挖掘系统的交互性
④数据挖掘中的信息保护与数据安全
⑤探索新的应用领域
⑥数据挖掘结果的可用性、确定性及可表达性
⑦可视化数据挖掘
3.数据挖掘的研究内容及功能
3.1数据挖掘的研究内容
数据挖掘所发现的知识最常见的有以下五类:
①广义知识(Generalizat ion)
广义知识指类别特征的概括性描述知识,反映同类事物共同性质,它是对数据的概括、精炼和抽象。
②关联知识(Association)
关联知识反映一个事件和其他事件之间依赖或关联的知识,又称依赖(Dependency)关系。
③分类知识(Classification&Clustering)
分类知识用来反映同类事物共同性质的特征型知识和不同事物之间的差异型特征知识
④预测型知识(Prediction)
预测型知识根据时间序列型数据,由历史的和当前的数据去推测未来的数据,也可以认为是以时间为关键属性的关联知识
⑤偏差型知识(Deviat ion)
偏差型知识是对差异和极端特例的描述,揭示事物偏离常规的异常现象,如标准类外的特例,数据聚类外的离群值等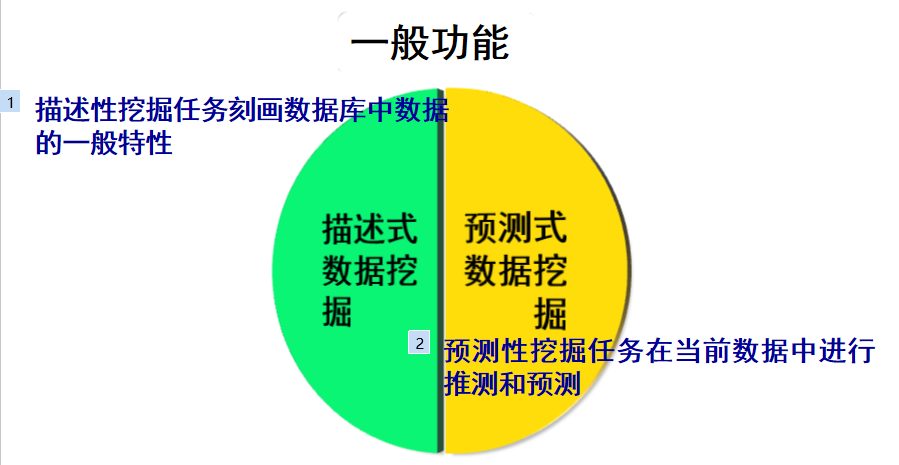
数据挖掘分类
不同的角度,不同的分类
- 待挖掘的数据库类型
- 待发现的知识类型
- 所用的技术类型
- 所适合的应用类型
所挖掘的知识
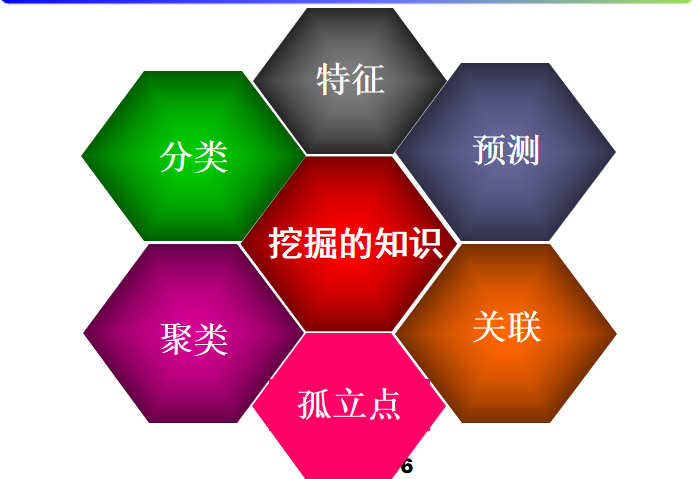
所用技术
机器学习,统计学,神经网络,数据库,可视化。
数据挖掘的功能主要体现在以下六个方面。
1.类/概念描述:特征化和区分
对含有大量数据的数据集合进行描述性的总结并获得简明、准确的描述,这种描述就称为类/概念描述(Class/Concept Description)。这种描述可以通过下述方法得到:
(1)数据特征化
(2)数据区分
(3)数据特征化和比较
2.关联分析
关联分析(Association Analysis)就是从给定的数据集中发现频繁出现的项集模式知识,又称为关联规则
3.分类和预测
分类(Classification)就是找出一组能够描述数据集合典型特征的模型(或函数),以便能够分类识别未知数据的归属或类别(Class)。
分类挖掘所获得的分类模型可以采用多种形式加以描述输出。其中主要的表示方法有:分类规则(IF-THEN)、决策树(Decision Trees)、数学公式(Mathematical Formulae)和神经网络。
分类可以用来预测数据对象的类标记。预测通常是指值预测,同时也包含基于可用数据的分布趋势识别。
4.聚类分析
聚类分析(无论是在学习还是在归类预测时)所分析处理的数据均是无(事先确定)类别归属的。
5.孤立点分析
大部分数据挖掘方法将孤立点视为噪声或异常而丢弃,但是孤立点可以使用统计试验检测。
6.演变分析
数据演变分析(Evolution Analysis)就是对随时间变化的数据对象的变化规律和趋势进行建模描述。
4.数据挖掘的常用技术及工具
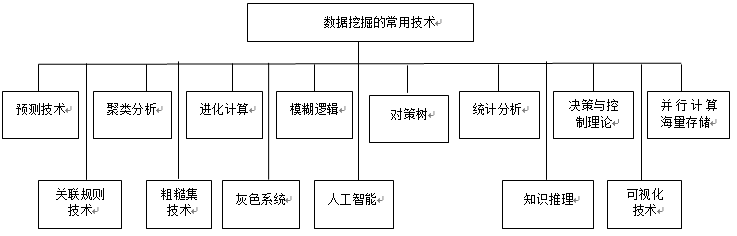
4.1 数据挖掘的常用技术
4.2 数据挖掘的工具
1、基于神经网络的工具
神经网络用于分类、特征挖掘、预测和模式识别。
2、基于规则和决策树的工具
其主要优点是:规则和决策树都是可读的。
3、基于模糊逻辑的工具
该方法应用模糊逻辑进行数据查询、排序等。
4、综合多方法的工具
这类工具一般规模较大,适用于大型数据库(包括并行数据库)
5.数据挖掘的主要问题
挖掘方法和用户交互
- 在数据库中挖掘不同类型的知识
- 结合背景知识
- 数据挖掘语言和启发式数据挖掘
- 在多个抽象层的交互式知识挖掘
- 数据挖掘结果的表示和可视化
- 处理噪音和不完全数据
- 模式评估:兴趣度问题
性能和可伸缩性
- 数据挖掘算法的性能和可伸缩性
- 并行、分布和增量的挖掘方法
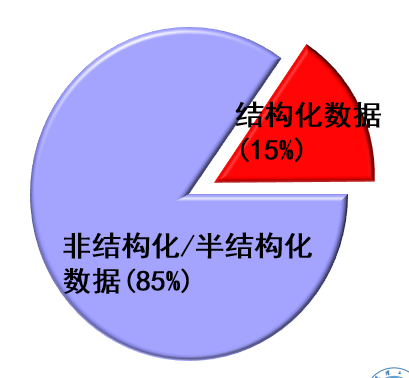
数据类型的多样性问题
应用和社会效果问题
- 发现知识的应用
- 特定领域的数据挖掘工具
- 智能查询回答
- 过程控制和决策制定
- 发现知识与已有知识的集成: 知识融合问题
- 数据安全, 完整和私有的保护